

The Push: May 2nd, 2026
Usernames that unravel identities, coding agents with managers, and screenshots that ship themselves


Maigret: Usernames Leak More Than You Think
github.com/soxoj/maigret | License: MIT
A handle that looks throwaway on one site often turns into a breadcrumb trail everywhere else. One username on GitHub, the same one on Reddit, then a niche forum, then an old photography profile with a personal site link, then a crypto account with a reused avatar. Maigret turns that messy manual search into a structured dossier, and that word is doing a lot of work here. This is not just vanity-name lookup. It is identity stitching across the public internet, fast enough to change how investigators, recruiters, journalists, and frankly stalkers think about usernames.
The Drop: The Internet Never Forgot Your Alias
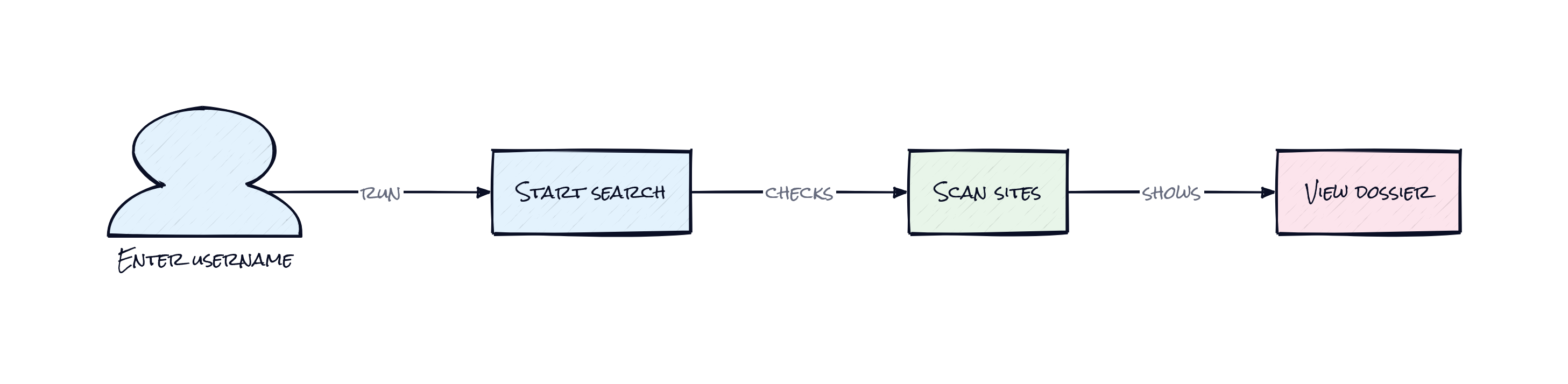
Typing the same username into a dozen sites feels manageable, until the search surface explodes. Social networks are obvious, but then there are coding platforms, regional forums, dating apps, art communities, gaming sites, crypto tools, and random services nobody remembers signing up for. Each one has different URL patterns, different error pages, different bot protection, and different clues hidden inside profile pages.
Maigret exists because username search is deceptively annoying. The easy part is checking whether an account exists. The painful part is doing it reliably across 3,000 plus sites, then pulling extra signals from the pages that do match. A profile might reveal links to other accounts, alternate IDs, a real name, location hints, or domain names. That means one match often creates three more leads.
Plenty of tools stop at “found” or “not found.” Maigret goes after the next question, which is the one that matters: what does this cluster of public traces actually say about a person?
The Stack: Python With a Very Wide Net
Under the hood, Maigret is built in Python, with aiohttp and async execution handling large batches of site checks without turning the search into a waiting game. A bundled and auto-updated site database powers the detection logic, while socid extractor pulls extra identity clues from matched pages and the built-in web app renders results as reports and graphs.
The Sauce: A Search Engine Made of Site Knowledge
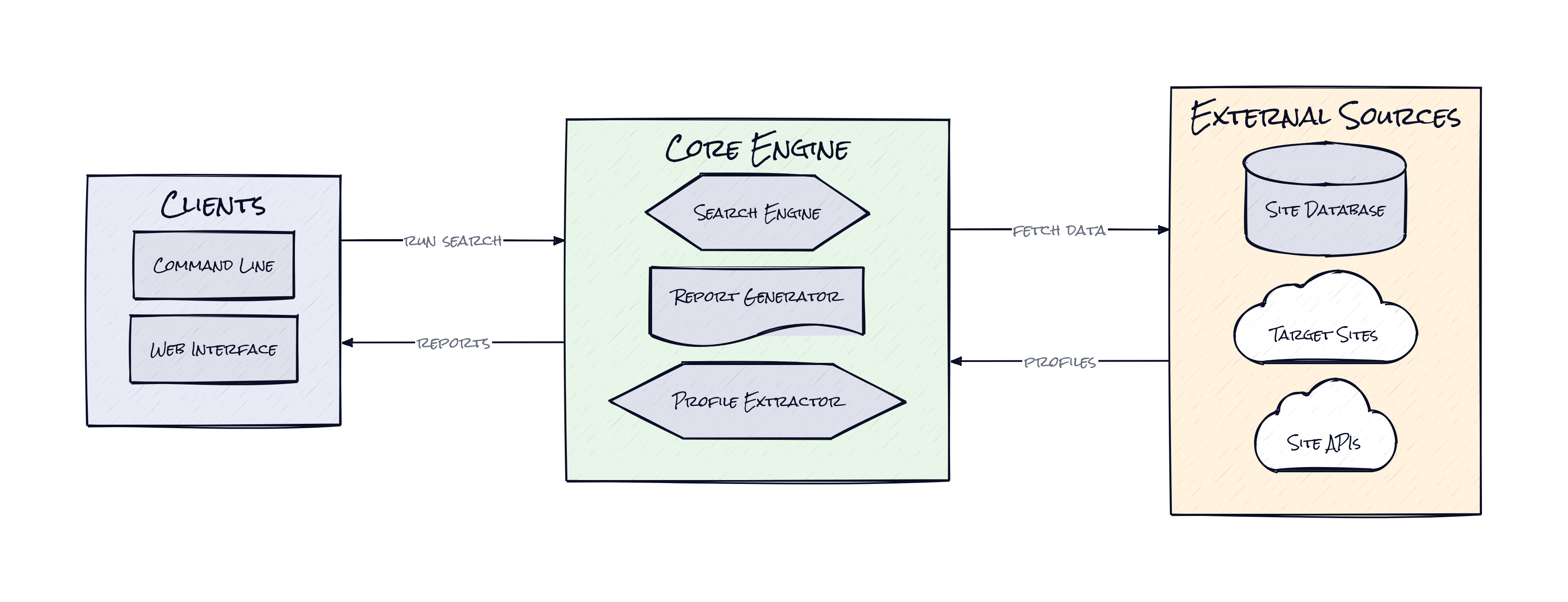
What makes Maigret interesting is the site database, not the command line. That database is a living registry of how thousands of websites expose profile existence, absence, and metadata. Each entry encodes the detection strategy for a specific service, including the profile format, the signals that mean “claimed” versus “unclaimed,” category tags, and enough context to keep false positives from wrecking the results.
That architecture matters because username search breaks in subtle ways. One site returns a clean 404, another serves a generic success page, another blocks bots, another swaps in a CAPTCHA, another hides useful data in the HTML even when the profile is half-public. Maigret handles that by treating every website like its own mini protocol, then running those checks concurrently. The result is less like a scraper and more like a distributed identity resolver.
Even better, Maigret does recursive search. When one profile exposes another username, ID, or linked account, the system can expand the graph rather than stopping at the first layer. That turns a static lookup into a lightweight investigation engine. Add the tag filtering system, which narrows searches by country or category, and the repo starts to feel very practical for real workflows, e.g. brand protection, threat intel, founder diligence, or fraud review. Honestly, the valuable idea is not raw coverage. It is encoding public identity logic into a reusable, constantly updated map.
The Move: Turn Public Clues Into Workflow Advantage
Security teams can use Maigret to tighten incident response the moment a suspicious alias appears in logs, chat rooms, or breach data. A single run can surface connected accounts, likely interests, geographic hints, and platform preferences, which is exactly the kind of context that speeds up triage when minutes matter.
Journalists and researchers get a different edge. Instead of burning an afternoon manually hopping across tabs, they can produce a report, inspect the graph, and decide where human judgment is actually worth spending. That is a better division of labor. Let software do the repetitive identity correlation, then let people handle verification and narrative.
Founders and product teams should pay attention too. Username reuse is a weirdly underexploited signal for trust, fraud, and onboarding. Embedding Maigret as a library means an app could enrich risk scoring, flag impersonation, or pre-fill public profile context for high-trust communities. That is where the repo gets strategic. The win is not “search usernames faster.” The win is compressing open web reconnaissance into something productizable.
The Aura: Pseudonymity Gets Harder to Maintain
Online identity used to feel fragmented by default. A username on one platform stayed there unless somebody had the patience to chase it manually. Tools like Maigret lower that patience threshold to almost zero, which changes behavior fast. People start treating handles less like disposable aliases and more like portable reputation objects, whether they want to or not.
That cuts both ways. Better trust and verification become possible, especially for investigations and fraud prevention. But privacy by obscurity gets weaker every time public traces become easier to connect. The bigger takeaway is simple: the internet increasingly rewards consistency and punishes careless reuse.
The Play: OSINT Infrastructure, Not Just a Utility
This looks less like a 0-to-1 category creation and more like a strong open-source wedge into the existing OSINT and digital investigation market. TAM is real because the downstream buyers are broad, cyber firms, compliance vendors, insurer SIUs, journalists, brand protection teams, and law enforcement tooling. PMF signals are already visible: 22,000 plus stars, meaningful forks, clear documentation, and evidence that commercial products build on top of it.
The moat is not classic network effects. It is execution speed on a messy, decaying surface area, plus a maintained knowledge base of site-specific detection patterns. That can be sticky if Maigret becomes the default enrichment layer inside other products, where switching costs rise through workflow integration and trust in result quality.
Winners:
Harmonic: Faster founder and company identity enrichment improves diligence depth, and the compounding advantage shows up in better proprietary profiles per analyst hour.
SentiLink: Stronger alias resolution across public accounts can sharpen fraud models, especially when synthetic identities leak behavioral traces across niche platforms.
CrowdStrike: Broader open web identity correlation can enrich threat intel pipelines and make attribution workflows more valuable without meaningfully increasing CAC.
Losers:
SocialCatfish: Commodity username discovery gets cheaper in open source, which erodes pricing power on the entry-level lookup use case and makes differentiation harder.
Life360: Trust and safety products that rely on weaker public identity stitching risk looking thin if better reconnaissance becomes easy to embed elsewhere.
Thomson Reuters: Premium investigative data products face pressure at the lower end when open-source tooling handles more of the first-pass correlation work.
tl;dr
Maigret turns a single username into a cross-site public identity search engine, then pushes further by extracting linked clues and expanding the search recursively. The clever part is the maintained site knowledge layer, not just the scraping. Security teams, researchers, and trust product builders should look closely.
Stars: 22,318 | Language: Python
