

The Push: May 21st, 2026
A sturdier toolkit for local agents, browser-debugging copilots, and scriptable research workflows


Forge: Small Models Need Adult Supervision
github.com/antoinezambelli/forge | License: MIT

Running a local model feels great right up until it has to do actual work. Drafting text is easy. Calling tools in the right order, across multiple steps, without mangling arguments or forgetting what just happened, that is where the wheels usually come off. Forge exists for that exact failure mode. Instead of chasing a bigger model or paying an API bill, this repo adds a reliability layer on top of self-hosted setups, turning a cheap local model into something that behaves a lot more like a disciplined agent.
The Drop: Where Local Agents Usually Break
Plenty of teams want the privacy and cost profile of self-hosted AI, but the minute those models need to interact with software, e.g. search, CRM actions, internal tools, or a customer support workflow, reliability drops fast. A small model might call the wrong tool, skip a required step, produce malformed arguments, or just answer in plain text when a tool call was needed. That is not a cosmetic bug. That is the difference between an assistant that demos well and one that can be trusted in production.
Forge is built around a pretty sharp observation: local models are often good enough at reasoning, but brittle at workflow discipline. The repo targets that gap directly. Not by pretending an 8B model suddenly became frontier-grade, but by wrapping the model in guardrails that keep it inside a predictable operating envelope. That matters because the real blocker for self-hosted agents is rarely raw intelligence. It is consistency under pressure, especially once memory limits, streaming, retries, and multi-step logic all collide.
The Stack: Python, but Very Systems-Minded
Under the hood, Forge is a Python framework with support for Ollama, llama.cpp via llama-server, Llamafile, and even Anthropic as a benchmark or hybrid backend. The architecture leans on asyncio, Pydantic-style structured schemas, and an OpenAI-compatible proxy that lets existing clients plug in without rewriting their app stack.
The Sauce: Forcing the Model to Stay in Bounds
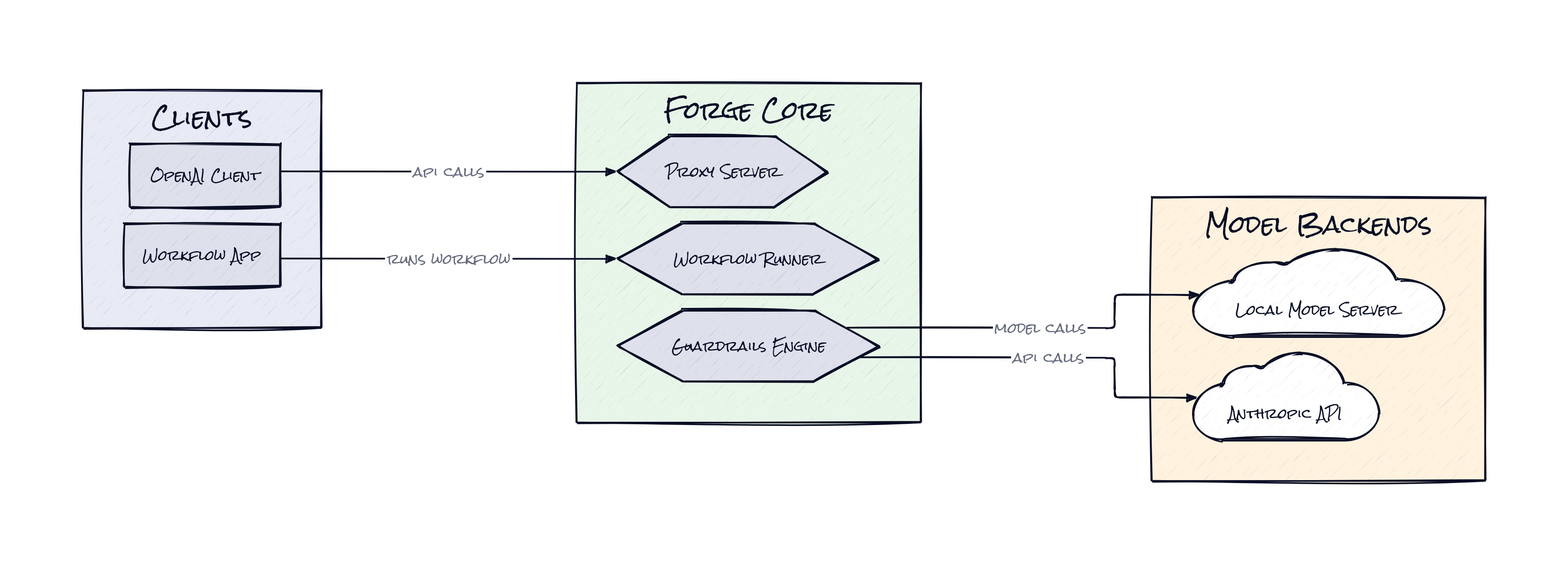
Buried inside Forge is a design choice that feels way more important than the repo’s headline features: the system treats tool use as the primary interface, not an occasional capability. That shows up in several places, but the standout is the synthetic respond tool. When a client sends tools, Forge silently injects a fake response tool so the model always stays in tool-calling mode, even when it just wants to answer with text. Then Forge strips that tool back out before returning the result.
That sounds small. It is not. Tiny local models are notoriously bad at deciding when to emit plain text versus structured tool calls. By collapsing both behaviors into one pathway, Forge removes an entire class of ambiguity. Everything can be validated, retried, and corrected through the same loop. That is clever architecture, because it turns an unreliable choice into a controlled protocol.
Around that, Forge layers rescue parsing, which recovers malformed tool calls instead of failing hard, step enforcement, which nudges the model back toward required workflow stages, and TieredCompact, a context strategy that shrinks history based on VRAM-aware budgets instead of naive truncation. Add the shared WorkflowRunner and proxy path, and the repo ends up acting like a reliability shim between any client and any local model server. Honestly, the interesting part is not “agent framework.” It is protocol design for undisciplined models.
The Move: Turn Cheap Inference Into a Usable Product
Founders and product teams could use Forge in three pretty different ways. The obvious one is building a self-hosted assistant that touches real systems, e.g. internal ops copilots, support agents, or workflow automation tools where data cannot leave the environment. In that setup, Forge gives a smaller model enough operational discipline to actually complete tasks, not just sound convincing.
Another strong move is the proxy route. Existing tools that already speak OpenAI-style APIs can be pointed at Forge and instantly gain guardrails middleware without changing the front end. That means a company using local inference for coding, document processing, or internal chat can improve reliability without rebuilding its whole stack. That kind of drop-in upgrade usually wins.
There is also a resource strategy here. The SlotWorker concept, which queues specialists onto a shared inference slot with preemption, makes single-GPU deployments more practical for multi-agent setups. Instead of buying more hardware, teams can squeeze more dependable behavior out of the hardware they already have. In a market obsessed with model quality, Forge is a reminder that orchestration quality can be the cheaper edge.
The Aura: Trust Becomes a Product Feature
People stop babying software once it behaves consistently three or four times in a row. That is the deeper thesis here. Forge is not trying to make local AI feel magical. It is trying to make local AI feel boringly dependable, which is what actually changes behavior inside a company.
Once that trust exists, smaller models become viable in places where they were previously dismissed as toys. Private deployment stops being just an ideological preference and starts looking like a serious product choice. The emotional shift is subtle but big: less “watch this demo” and more “hand this system a workflow and expect it to finish.”
The Play: Reliability Is Its Own Market
This looks less like a 0-to-1 category and more like a wedge into a fast-growing existing TAM: the infrastructure layer for production AI agents, especially self-hosted ones. The PMF signal is early but real. More than 1,400 stars on a repo created recently, a detailed eval suite, extensive tests, and multiple integration modes suggest users are not just browsing, they are trying to ship. The moat is not raw code defensibility. It is execution speed, eval data, and the habit loop created when teams standardize on one reliability layer across local models and clients.
Winners:
Lamatic: Better local-agent reliability lowers infra anxiety for workflow startups, and that compounds into lower CAC when privacy-sensitive buyers finally say yes.
Harvey: More dependable self-hosted tool use expands enterprise deployment options, especially where legal data handling makes cloud-only AI a harder sell.
Microsoft: Stronger local agent stacks make Windows and enterprise edge hardware more attractive as AI execution surfaces, not just access points to cloud models.
Losers:
Adept: Generic agent orchestration loses shine when open source reliability layers handle the messy operational bits that once justified a premium story.
Moveworks: Closed enterprise assistants face margin pressure if customers can assemble trustworthy internal agents on cheaper self-hosted foundations.
OpenAI: API default status weakens at the edge when more teams realize the sticking point was workflow reliability, not always model intelligence.
tl;dr
Forge turns flaky self-hosted tool-calling into something much more production-friendly. The smart part is its unified control layer, especially the synthetic response tool that keeps small models inside a validated workflow. Worth a look for anyone building local assistants, internal copilots, or AI products with privacy constraints.
Stars: 1,414 | Language: Python
