

The Push: May 18th, 2026
Portable local models, agent-ready CLIs, and safer shared skills for teams tired of AI duct tape


Llama Cpp: Open Models Need a Runtime
github.com/ggml-org/llama.cpp | License: MIT

ChatGPT feels magical until the bill shows up, the latency spikes, or legal asks where the data actually went. Then the glamour wears off fast. A lot of teams want the upside of large models without handing every interaction to a hosted API. That sounds simple, until the reality hits: model formats are messy, hardware is fragmented, and local inference usually means wrestling with GPU drivers or praying a MacBook can keep up. Llama Cpp became the project people reach for when they want open models to behave like software, not research artifacts.
The Drop: The Runtime Gap Nobody Wanted
Open-weight models exploded, but actually running them stayed weirdly brittle. Labs shipped checkpoints, Hugging Face filled with variants, and every benchmark thread implied local inference was one command away. In practice, teams hit a wall. A model that works on an NVIDIA box might choke on Apple silicon. Something that fits in cloud VRAM might be unusable on a laptop. Even worse, the packaging around models often mattered as much as the model itself.
That gap is what pushed Llama Cpp into the center of the ecosystem. The problem was never just “make models faster.” The problem was turning a chaotic pile of weights, quantization tricks, hardware backends, and half-compatible tooling into a dependable runtime. Product teams need something they can embed in an app, ship in a desktop product, or expose through an API without rebuilding the entire inference stack from scratch.
Honestly, the frustration here feels similar to the early browser wars or mobile fragmentation. The model gets headlines. The runtime determines whether anyone can actually use it.
The Stack: C++ as Distribution Strategy
Under the hood, Llama Cpp is mostly C/C++, built around the ggml tensor library and optimized across CPUs, Apple Metal, CUDA, Vulkan, SYCL, and more. The project also leans on GGUF, a model packaging format that bundles weights and metadata in a way downstream tools can actually consume cleanly.
The Sauce: GGUF Turned Models Into Portable Products
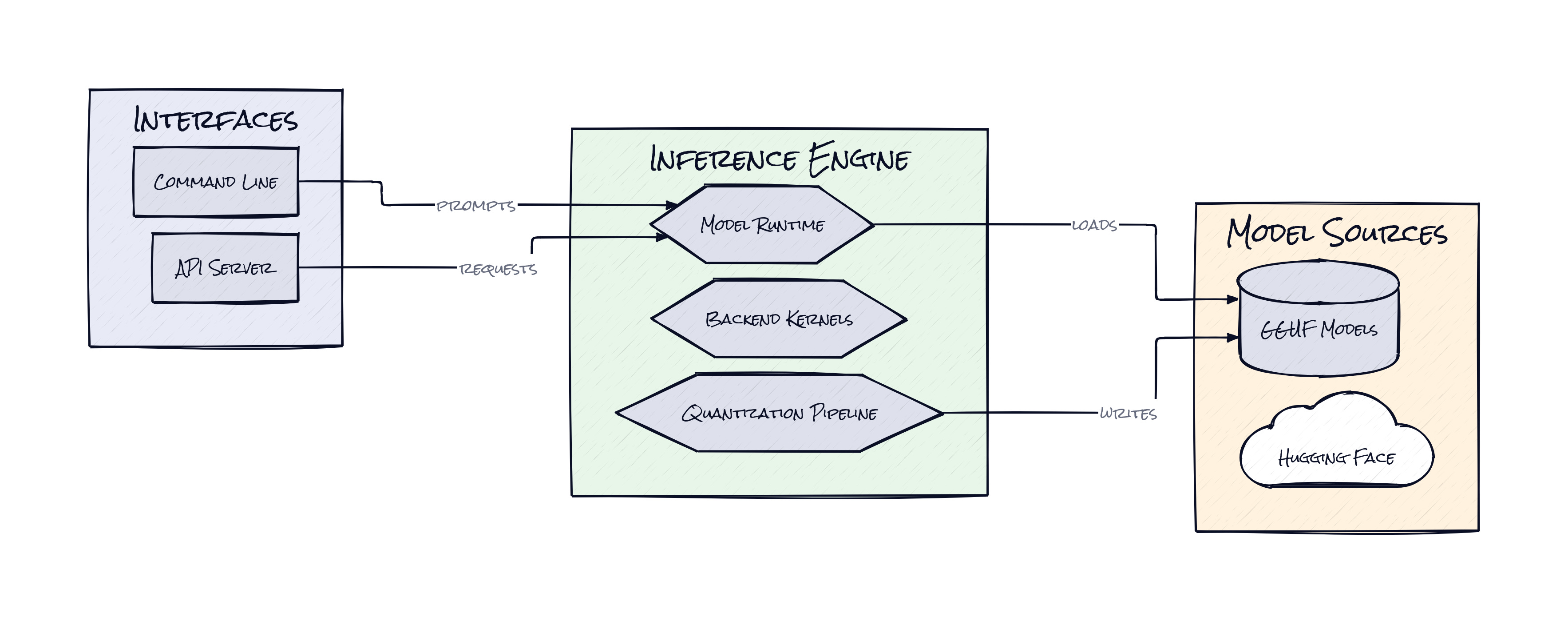
What makes Llama Cpp interesting is not raw speed alone. The architectural bet is GGUF, because that format turns model distribution into something much closer to app distribution. Instead of treating a model as a loose collection of research outputs, GGUF packages the weights, tokenizer metadata, and runtime-relevant details into a single artifact that multiple tools can load predictably.
That matters because portability is the hidden tax in open AI. A model is only valuable if it can move from a Hugging Face page to a laptop app, an edge device, a local server, or a desktop coding assistant without bespoke conversion drama every time. Llama Cpp sits at that portability layer. The project standardizes how inference engines, quantized variants, and hardware-specific optimizations meet in one place.
The second smart decision is how broad the backend abstraction has become. Apple silicon is treated as a first-class target, not an afterthought, while NVIDIA, AMD, Vulkan-capable systems, and CPU-only setups all get serious support. That means the runtime is not tied to one chip vendor’s roadmap. Add quantization into the mix, shrinking models into lower-bit representations so they fit on consumer hardware, and Llama Cpp starts acting like the compatibility layer for open models.
That is why so many tools quietly build on top of it. Not because everyone wants a command line toy, but because a stable inference substrate is harder to build than the chat UI.
The Move: Use It Where Margins Matter
Founders and product teams can use Llama Cpp in three especially high-leverage ways. First, run smaller or quantized open models locally for privacy-sensitive workflows, e.g. note-taking, enterprise search, legal review, or offline copilots. That cuts per-call API spend and gives much tighter control over data residency.
Second, use the built-in server layer to expose an OpenAI-compatible endpoint inside an internal stack. That move is sneaky powerful. Existing products can test open models without rewriting the whole application layer, because the interface looks familiar to tools already built around hosted APIs.
Third, treat Llama Cpp as the experimentation surface for model strategy. Teams can compare Gemma, Qwen, Mistral, Llama-family variants, or multimodal models on their own hardware and with their own prompts. That means vendor selection stops being a slide deck exercise and becomes an operational decision tied to cost, latency, and reliability.
The strategic edge is simple: whoever controls inference options controls margin, privacy posture, and negotiating power with model providers.
The Aura: AI Stops Feeling Rented
People get attached to software that works on their machine, with their data, on their terms. That is the deeper appeal here. Llama Cpp lowers the psychological barrier between “AI as a service” and “AI as a capability.”
Once that line blurs, expectations change. Users start assuming intelligence should be available offline, embedded, and customizable, not permanently metered by someone else’s cloud. The bigger thesis is not just cost savings. It is agency. Software starts feeling owned again, even when the underlying models are changing every few months.
The Play: Infra Picks and Shovels, Not a Toy
From a VC lens, this is not a consumer app and not exactly a pure 0-to-1 category either. It is a foundational open runtime in a massive TAM, basically the compute and deployment layer for the open-model economy. The PMF signals are obvious: 110,000-plus stars, heavy forks, constant hardware contributions, and broad downstream adoption. The moat is mixed. Core code can be copied, but ecosystem position, format gravity around GGUF, and relentless execution across hardware backends create real staying power. Behavior change also looks sticky, because once a team ships local or self-hosted inference, unit economics and compliance incentives keep them there.
Winners:
Jan: Lower deployment friction for local AI clients compounds into distribution, because a trusted runtime makes desktop inference usable for non-experts.
Ollama: Faster model support and broader hardware compatibility strengthen product velocity, which improves retention as open-model demand spreads beyond hobbyists.
Hugging Face: More runnable open models increase repository value and traffic, and GGUF support deepens the platform’s role as the default distribution hub.
Losers:
Fixie: Hosted agent infrastructure gets squeezed when teams can run capable open models locally, and differentiation gets harder without proprietary data loops.
Together AI: Inference revenue faces margin pressure as more workloads shift on-device or on-prem, especially for smaller always-on use cases.
OpenAI: Premium API pricing looks less durable when developers and enterprises gain credible self-hosted substitutes for a widening slice of tasks.
tl;dr
Llama Cpp turns open models into something portable, efficient, and deployable across messy real-world hardware. The clever part is the combo of GGUF packaging, aggressive quantization, and broad backend support, which makes local inference feel practical instead of aspirational. Worth a look for anyone betting on private, cheaper, or embedded AI.
Stars: 110,902 | Language: C++
