

The Push: May 16th, 2026
Browser-rendered video, process causality, and repo maps that help AI stop guessing and start navigating


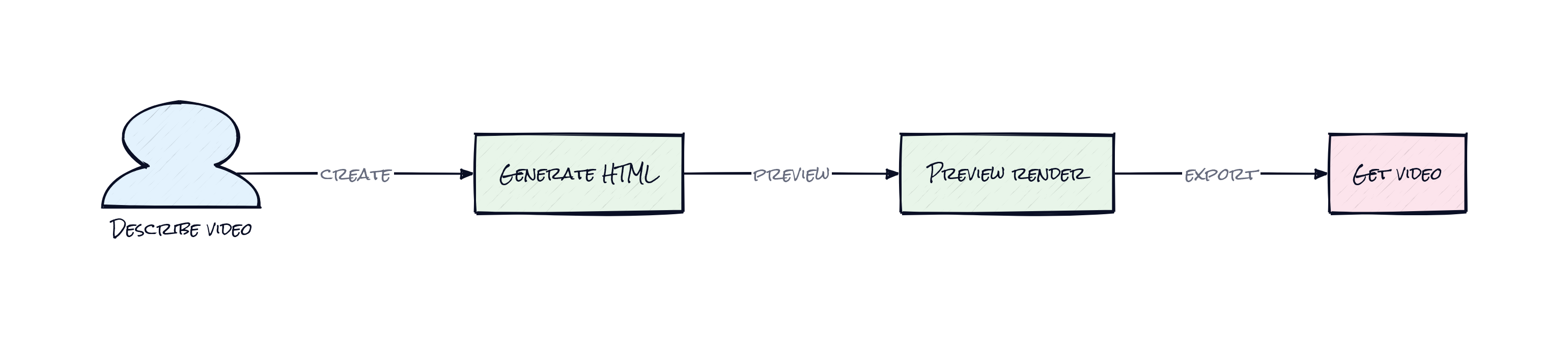
HyperFrames: Video Generation Without the Cage
github.com/heygen-com/hyperframes | License: Apache-2.0

A weirdly common bottleneck in AI workflows is the last mile: the model can write a script, draft visuals, even suggest motion, then everything falls apart when the output needs to become an actual polished video. Suddenly you're back in timeline software, dragging layers around like it's 2014. HyperFrames takes a sharper bet. Let HTML be the source of truth, let agents write it, and let the browser render the motion. That sounds obvious in hindsight, which is usually a sign somebody found the right abstraction.
The Drop: Where Video Authoring Still Breaks
Scroll through AI video demos and a pattern shows up fast. The flashy part is generation, but the painful part is control. Text-to-video tools are decent at mood, terrible at precision. Traditional editors are precise, but not agent-friendly, automatable, or especially reusable. And code-based video tools often ask for React components, which is fine for developers but awkward for anyone trying to turn existing web assets, brand pages, dashboards, or AI-produced HTML into motion without rewriting everything.
HyperFrames exists because teams already have visual systems in HTML and CSS, and agents already know how to produce those formats surprisingly well. The gap was rendering them into deterministic, repeatable video output. Not "something close enough," but the same output every time, suitable for pipelines, previews, and automation. That matters if you're generating product explainers from docs, social clips from data, or personalized videos at scale. The frustration wasn't a lack of video tools. It was that the web stack and the video stack kept acting like separate worlds.
The Stack: Browser-Native, Pipeline-Ready
Under the hood, HyperFrames is mostly TypeScript, with a CLI and rendering engine that drive headless Chrome and FFmpeg. Animation support plugs into familiar web runtimes like GSAP, CSS animations, Lottie, and Three.js, while the project also ships agent-facing skills and plugin manifests for Claude Code, Cursor, and Codex.
The Sauce: HTML as the Contract
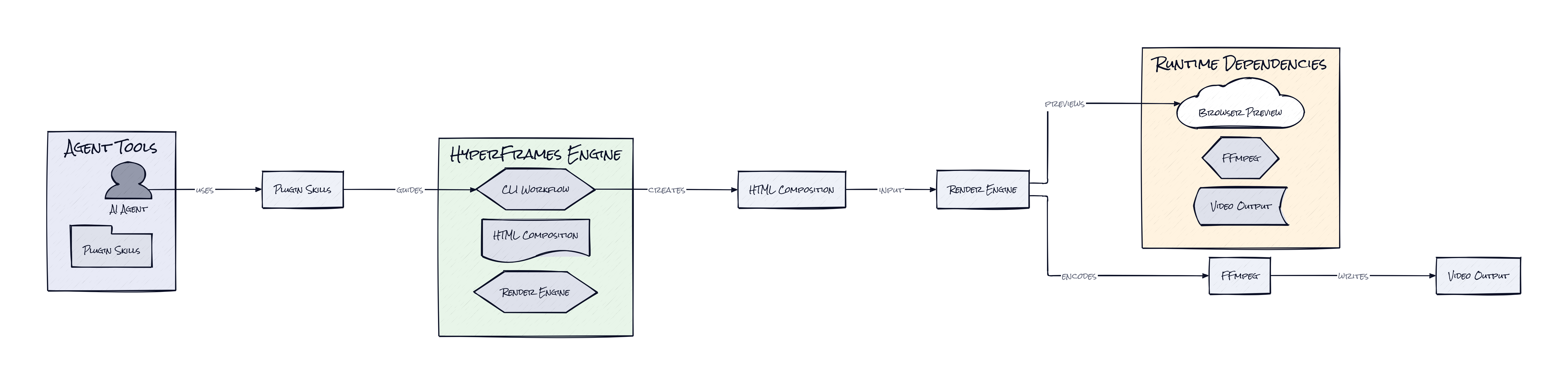
HyperFrames centers everything on an HTML-native composition model, and that's the decision that makes the whole repo click. A video isn't declared in a proprietary format or a UI timeline export. It's expressed as ordinary HTML elements annotated with timing, sizing, and track metadata, then interpreted by a rendering runtime that treats the browser as a deterministic stage rather than a freeform playback environment.
That sounds subtle, but it changes who can author video and how the system composes with AI. Agents are already strong at generating HTML, CSS, and structured attributes. Asking a model for a valid video scene in HTML is far closer to its training distribution than asking for a bespoke motion DSL. HyperFrames leans into that with skills, which are packaged instruction layers for coding agents, plus plugin surfaces for different agent environments. In practice, that means the repo is not just a renderer, it's a teaching layer that helps agents produce output the engine can trust.
The second smart move is the Frame Adapter pattern. Rather than forcing one animation runtime, HyperFrames standardizes how different motion systems sync to render time. That matters because browser animation libraries usually run on wall-clock time, while video rendering needs exact frame seeking. HyperFrames bridges that mismatch, so a GSAP timeline or other animation source can be sampled consistently during render. Honestly, that's the interesting part: not HTML video by itself, but a browser-motion stack made reliable enough for automation.
The Move: Turn Content Systems Into Video Systems
Plenty of teams already sit on structured content that wants to become motion: product launch pages, benchmark charts, onboarding flows, investor updates, even support docs. HyperFrames gives those teams a way to convert existing web-native assets into repeatable video templates instead of commissioning every output from scratch. That lowers production cost, sure, but the strategic advantage is throughput. Once a composition exists, an agent can remix copy, swap assets, localize narration, and regenerate variations without reopening a timeline tool.
Founders and PMs should read this as a content infrastructure play, not a creator toy. A growth team could turn feature flags into announcement clips. A sales org could generate account-specific intros. An education company could convert lesson summaries into short explainers. Because the render path is deterministic, those outputs fit into approval and QA workflows better than generative video tools that drift every run. HyperFrames seems especially useful anywhere brand consistency matters more than cinematic originality, e.g. B2B marketing, product education, and high-volume personalized media.
The Aura: Software That Can Present Itself
Static documents are starting to feel unfinished. A spec, dashboard, or launch memo no longer has to just sit there waiting for a human to translate it into a more persuasive format. HyperFrames pushes toward a world where software can present itself, with motion, timing, voice, and packaging built directly from the same source material. That changes expectations fast.
People may start treating video less like a handcrafted asset and more like a compiled artifact. Not disposable, not sloppy, just generated from structured intent instead of assembled manually every time. The human shift is subtle but big: communication becomes something systems can format dynamically, not just something teams ship after a creative bottleneck.
The Play: Open Source Attacks the Video Pipeline
This looks less like a 0-to-1 category creation and more like a smart wedge into a very real market: programmable video infrastructure for AI-native workflows. TAM is broad, spanning creator tooling, marketing ops, sales enablement, education, and enterprise communications. The PMF signal is loud for a young repo, 18,588 stars almost immediately, clear differentiation versus Remotion, and distribution hooks into major agent environments. The moat is not raw code defensibility, because HTML rendering can be copied. The moat is execution speed, ecosystem fit, agent distribution, and eventually the template, plugin, and workflow layer that compounds usage into switching costs.
Winners:
Pika: Faster iteration on structured, template-driven outputs compounds because teams will want controllable motion systems sitting alongside generative video, not replacing them.
Synthesia: Stronger enterprise positioning grows if programmable scenes and personalized outputs become table stakes for training and internal communications.
Adobe: Broader demand for web-to-video workflows helps incumbents that can absorb agent-driven authoring and distribution into existing creative pipelines.
Losers:
Tella: Narrower room for lightweight recording-first products emerges as AI-generated explainers get easier to template and automate from existing content.
Runway: Higher pressure lands on pure generation narratives when buyers start asking for deterministic edits, reusable layouts, and system-level control.
Canva: More value leaks out of slide-and-timeline interfaces if the source material for motion increasingly starts as structured HTML and agent-authored assets.
tl;dr
HyperFrames turns HTML into deterministic video renders, then layers agent skills and browser-native animation on top so AI can actually author polished motion assets reliably. The clever bit is treating the browser as a frame-accurate video engine, not just a preview surface. Worth a look for teams building content pipelines, personalized media, or agent-driven marketing ops.
Stars: 18,589 | Language: TypeScript
