

The Push: May 13th, 2026
Modular telemetry, crypto strategy engines, and science-savvy AI skills for operators, traders, and research teams


Telegraf: Observability’s Swiss Army Knife
github.com/influxdata/telegraf | License: MIT

A weird amount of modern infrastructure still runs on duct tape between dashboards. One service emits Prometheus metrics, another dumps logs to files, a factory device speaks OPC UA, and some ancient box only answers SNMP. Then someone asks for one clean view of system health by Monday. That is the moment Telegraf becomes interesting. Not because telemetry collection is glamorous, it really isn’t, but because the expensive part of observability is often not storage or charts. It’s getting messy, mismatched data into one pipeline without building a custom connector graveyard.
The Drop: The Data Plumbing Nobody Wanted
Monitoring tools love the demo where every system already speaks the right format. Real companies do not. A cloud app might expose metrics cleanly, while warehouse hardware sends industrial data through protocols built for another era, and internal services scatter useful signals across logs, message queues, and SQL tables. The result is familiar: teams buy one observability platform, then quietly spend months writing glue code just to make the platform usable.
Telegraf exists because telemetry sprawl is operational debt. Not flashy debt, but the kind that slows every incident response and every reporting project. One-off scripts break, vendor agents cover only their own stack, and every new source creates another integration decision. Honestly, the pain is less about collecting CPU stats and more about normalizing the long tail of everything else, e.g. network gear, edge devices, Kafka streams, Windows event logs, and random HTTP endpoints. Telegraf steps into that mess as a universal collector, processor, and forwarder. The repo’s appeal is simple: stop rebuilding the ingestion layer every time another system starts talking.
The Stack: Go Everywhere, Connect Everything
Under the hood, Telegraf is written in Go, which fits the job: small binaries, easy deployment, low runtime drama. Configuration lives in TOML, and the core architecture revolves around a giant plugin surface for inputs, processors, aggregators, and outputs, with integrations spanning Kafka, MQTT, Prometheus, OpenTelemetry, SQL, and a long tail of infra and industrial protocols.
The Sauce: Plugins as the Product Surface
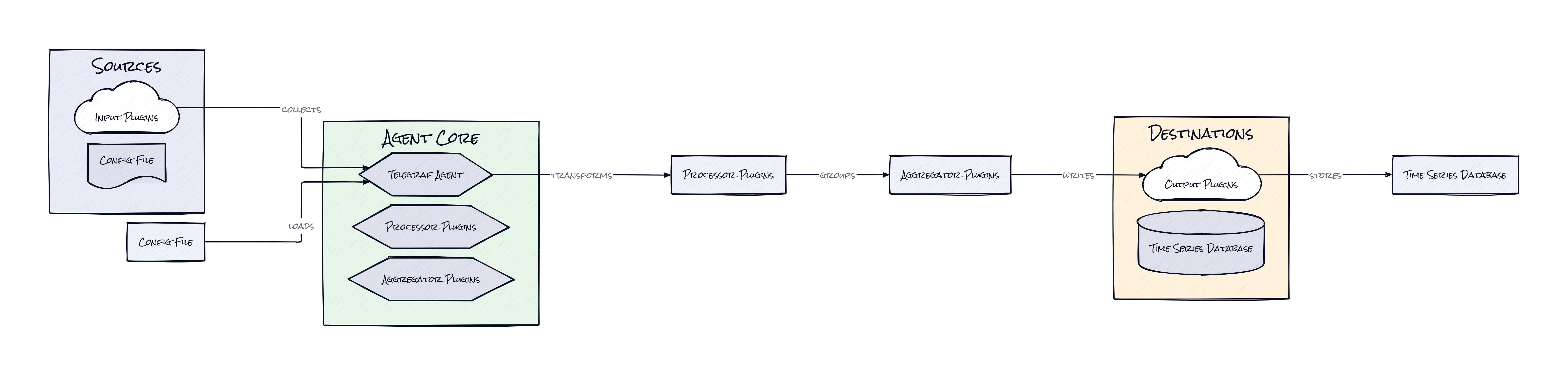
Three layers make Telegraf more than “yet another agent”: inputs, processors, and outputs. That sounds obvious until looking at what this structure buys. Telegraf does not treat collection as a one-way scrape into a single database. It treats telemetry as a modular pipeline where data can be gathered from many sources, transformed in transit, optionally aggregated, then shipped to many destinations. That architectural choice is why the repo has lasted.
A lot of telemetry tools win on one end of the pipe. Prometheus is great at scraping. Datadog is great at productizing the back end. Vector is strong on logs. Telegraf’s clever move is owning the connective tissue between worlds. Because plugins exist at multiple stages, the same agent can read from industrial systems, enrich fields, reshape payloads, filter noise, and forward to InfluxDB, Kafka, Elasticsearch, or whatever stack already exists. That makes Telegraf less like a single-purpose collector and more like middleware for machine data.
Community scale matters here too. More than 300 plugins means the architecture compounds with every edge case someone else already hit. A plugin system is only impressive if it keeps reducing integration cost over time. Telegraf seems to do exactly that. The static binary angle helps as well: less dependency drama, easier rollout to edge environments, and fewer excuses from ops teams. The interesting part is not any one connector. It’s the decision to make telemetry routing itself the durable abstraction.
The Move: Turn Telemetry Into Optionality
Instead of buying a full observability suite upfront, Telegraf lets a team standardize collection first and postpone harder vendor decisions. That is a strategic move, not just a technical convenience. Drop Telegraf near workloads, edge devices, or on-prem systems, configure the relevant plugins, and start funneling signals into the destinations that already matter, e.g. a BI warehouse for business operations, Kafka for event pipelines, or a monitoring stack for incident response.
Founders and operators should notice the optionality here. Once one agent can speak to legacy hardware, cloud APIs, and modern telemetry systems at the same time, migrations get less scary. Switching back ends stops being a full re-instrumentation project. Teams can also create cleaner internal data products, piping operational metrics into forecasting, capacity planning, or customer-facing reliability features.
For companies with physical operations, Telegraf is especially useful because few tools comfortably bridge software telemetry and machine telemetry. A logistics business, energy startup, or industrial SaaS company could use Telegraf to unify signals that normally live in separate org charts. That shortens the path from raw infrastructure noise to actual operational intelligence. Quietly powerful is the right phrase.
The Aura: Infrastructure That Lowers Anxiety
Operators change behavior when data collection stops feeling fragile. Instead of asking whether a source can be integrated at all, teams start asking what new questions become answerable once everything is flowing. That matters because confidence in telemetry changes decision-making speed. Incidents get triaged faster, migrations feel less risky, and weird edge systems stop being invisible.
Telegraf also hints at a broader expectation: every machine, service, and queue should be legible by default. Not perfectly, not instantly, but without bespoke heroics. That psychological shift is bigger than observability. It nudges companies toward treating operational truth as something that can be composed, queried, and redirected, rather than trapped inside whichever vendor or protocol got there first.
The Play: Picks and Shovels With Real Staying Power
From an investing angle, Telegraf is not a clean 0-to-1 category creation. Telemetry collection is an existing market with serious incumbents. But this repo shows why the ingestion layer still has room for outsized value: the TAM spans cloud infrastructure, industrial IoT, cybersecurity, edge computing, and data engineering, all of which need normalized machine data before any higher-margin analytics product works. PMF signals are strong, with 16,942 stars, long-term contributor depth, and broad protocol coverage that usually only appears when a project is solving real pain repeatedly. The moat is not raw IP, it is plugin breadth, deployment trust, and the switching-cost advantage that appears once a company standardizes its telemetry edge on one agent.
Winners:
Abridge: Cleaner operational data across clinical systems compounds into faster integrations and lower deployment friction in messy hospital environments.
Samsara: Broader telemetry interoperability strengthens expansion from fleet tracking into a fuller operational data platform with higher LTV per customer.
Microsoft: More machine data flowing through standardized pipes increases demand for Azure analytics, security, and observability back ends.
Losers:
Groundcover: Narrower differentiation in collection erodes when open infrastructure handles more ingestion needs before buyers commit to a full platform.
Grafana Labs: Higher pressure lands on monetizing analysis and workflow layers as basic data intake becomes more portable across stacks.
Cisco: Appliance-centric monitoring value weakens when software agents get better at pulling telemetry out of heterogeneous network environments.
tl;dr
Telegraf turns telemetry collection into a modular pipeline instead of a pile of one-off agents and scripts. What’s clever is the plugin architecture across collection, transformation, aggregation, and delivery, which makes observability stacks far more portable. Worth a look for operators, infra teams, and founders dealing with messy real-world systems.
Stars: 16,942 | Language: Go
