

The Push: June 4th, 2026
Voice-first avatars, modular research notebooks, and embedded agent runtimes for apps that need AI to actually do stuff


Open LLM VTuber: AI Companions Get a Body
github.com/Open-LLM-VTuber/Open-LLM-VTuber | License: Other

A chatbot in a browser tab is easy to forget. A character sitting on the desktop, talking back in real time, reacting with facial expressions, and cutting itself off when interrupted feels weirder, and honestly much closer to what consumer AI keeps promising. Open LLM VTuber leans into that gap. Instead of treating voice, avatar, and model choice as separate hacks, it packages them into one local-first system that turns any LLM into an always-on presence. That difference matters more than the anime framing might suggest.
The Drop: The Chat Window Was Never Enough
Chat interfaces flatten everything. A model might be smart, fast, and personalized, but once the experience is reduced to text bubbles and a send button, the emotional range collapses. Voice assistants tried to fix that, but they usually sound transactional, break the moment you interrupt them, and route your entire life through someone else’s cloud.
Open LLM VTuber comes from a very specific frustration: people want an AI companion, streamer persona, or desktop character that feels continuous, not like a sequence of API calls. Existing tools split the experience into pieces. One app handles speech recognition, another does text-to-speech, another renders a Live2D avatar, which gives a 2D character facial motion and expressions, and another wraps an LLM. Then the whole thing falls apart under latency, compatibility issues, or privacy concerns.
That fragmentation is the actual bug. If the character cannot listen while speaking, cannot react visually, or cannot run offline, the illusion breaks instantly. Open LLM VTuber treats the companion as a single product surface, not a pile of model demos. That sounds obvious, but plenty of AI products still miss it.
The Stack: Python in the Back, Browser in the Face
Under the hood, Open LLM VTuber uses FastAPI and WebSockets on the backend, with Python coordinating model calls, audio flow, session state, and configuration. The front end handles microphone capture, streaming playback, and avatar rendering, while the system stays modular enough to plug into Ollama, OpenAI-compatible endpoints, Whisper-style speech recognition, and multiple TTS engines.
The Sauce: Streaming Is the Personality Layer
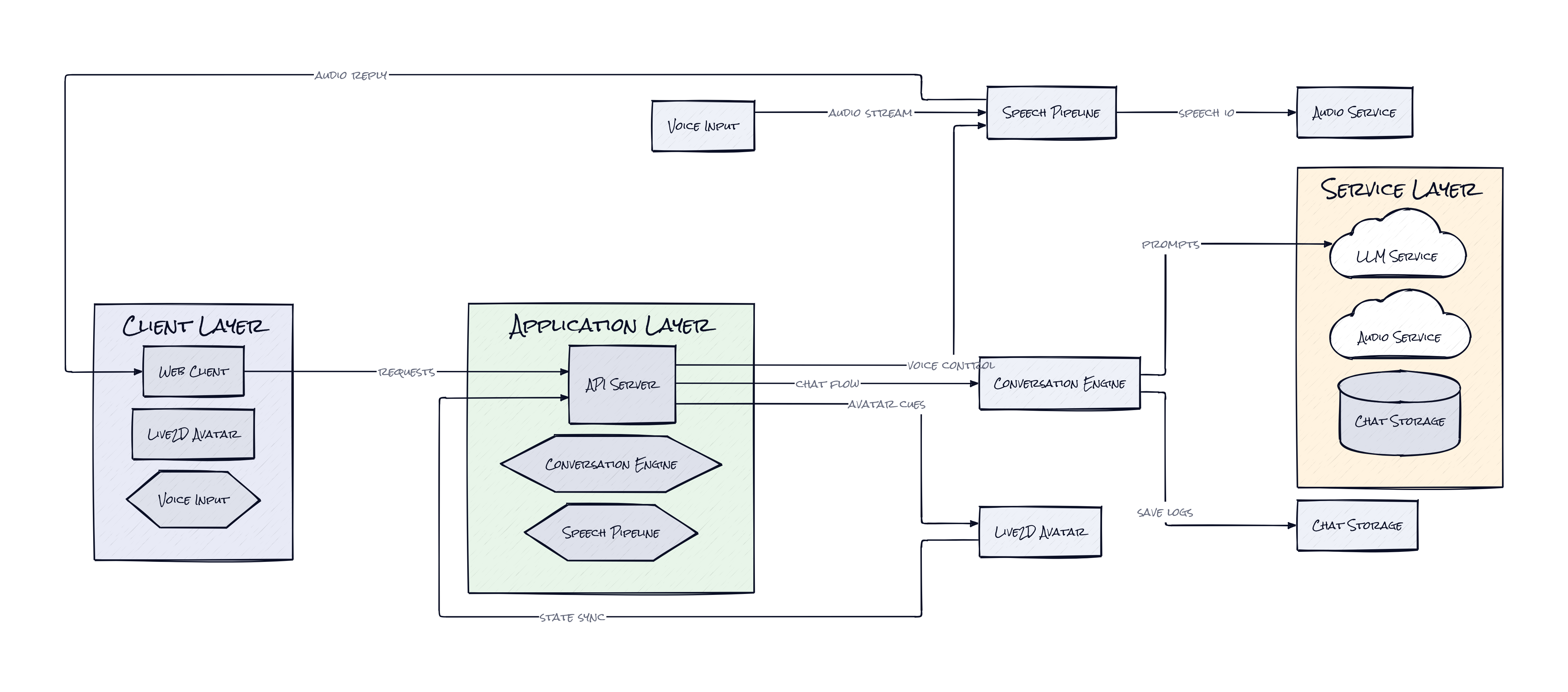
Latency does not just affect speed here, it shapes whether the character feels alive. Open LLM VTuber is built around a voice-interruptible loop, where speech input, model output, and synthesized audio stay active as a continuous stream rather than a neat request-response cycle. That architectural choice is the whole point.
Rather than waiting for a full transcription, a full model answer, and a fully rendered voice clip before showing anything, the project coordinates live audio capture, sentence segmentation, WebSocket messaging, and output playback so the system can speak quickly, stop quickly, and recover gracefully. That matters because human conversation is full of overlaps. People cut in, hesitate, change direction. A companion that cannot handle interruption feels less like a character and more like an IVR menu with better branding.
Another smart decision is the repo’s module configuration approach. Different users can swap in local or cloud LLMs, ASR, and TTS providers without rewriting the product’s core interaction model. That makes Open LLM VTuber less like a single app and more like a runtime for embodied AI personas. The desktop pet mode, which pins a transparent character above other windows, pushes that further. Presence becomes part of the interface.
Honestly, the interesting part is not the avatar art. It is the orchestration layer binding perception, speech, expression, and persona into one loop. Plenty of repos can call a model. Far fewer can stage a believable turn-taking experience.
The Move: Turn Personality Into Product Surface
Creators can use Open LLM VTuber to build a persistent on-screen host for livestreams, community spaces, or fan experiences without handing the full stack to a closed platform. A streamer can pair a custom persona, a cloned voice, and a local model for an AI sidekick that comments on gameplay, reacts to chat, and stays visually on-brand. That is not just novelty, it is content differentiation with lower marginal cost.
Teams building consumer AI should pay attention too. Open LLM VTuber is a fast way to test whether an assistant becomes more engaging when given embodiment, voice interruption, and ambient presence. Put one in a language-learning app, a wellness companion, a virtual tutor, or a game launcher. The question is not whether users want another text bot. The question is whether retention changes when the assistant feels socially available.
Founders can also treat the repo as a wedge into local-first AI experiences. Privacy-sensitive markets, e.g. education or mental health journaling, care about on-device interaction more than Silicon Valley often admits. A polished wrapper around this architecture could become a subscription product, a creator tool, or even branded character infrastructure for IP owners.
The Aura: People Bond With Responsiveness
Users forgive a lot when software feels attentive. A talking character that pauses when interrupted, remembers the flow of a conversation, and occupies a stable place on screen starts to trigger expectations borrowed from social interaction, not app usage. That is powerful, and a little unsettling.
Open LLM VTuber hints at a future where AI stops being something you open and becomes something that hangs around. Not omniscient, not fully autonomous, just persistently available. The behavioral shift is subtle: less “ask a tool,” more “live alongside a presence.” Once that expectation forms, plain chat boxes can start to feel oddly dead.
The Play: Embodied AI Is a Distribution Bet
From a VC lens, Open LLM VTuber looks less like pure 0-to-1 category creation and more like an aggressive unbundling of Character.AI, Inworld, and parts of the creator tooling stack. TAM is bigger than “anime companions” suggests, because the underlying market is consumer AI engagement, creator monetization, and branded interactive characters. Nearly 9,500 stars, active docs, multilingual community surfaces, and signs of a rewrite all point to real builder pull, not a weekend meme.
Moat is not deep data yet. The nearer-term moat is execution speed, community contribution, persona distribution, and sticky user behavior once a character becomes part of someone’s desktop or stream workflow. CAC can be low through fandom, modding, and creator channels. LTV gets interesting if personalization and asset packs layer on top.
Winners:
Hedra: Lower-cost character interfaces expand demand for AI-native video and persona tools, and that compounds as creators want custom faces, voices, and always-on agents.
Character.AI: More user familiarity with persistent AI personas grows the category, making premium character ecosystems easier to monetize if social attachment deepens.
Roblox: More believable user-generated characters increase the value of avatar identity, virtual goods, and AI-mediated experiences inside an already social platform.
Losers:
Tolan: Consumer companion differentiation erodes when open source makes local voice, presence, and persona customization cheaper to ship and harder to defend.
Inworld AI: Middleware pricing gets pressured when developers can assemble expressive character stacks themselves and keep more control over model and front-end choices.
Amazon: Alexa-style assistant expectations weaken further as users compare static smart-speaker interactions against expressive, interruptible AI characters with visible presence.
tl;dr
Open LLM VTuber turns any LLM into a local-first voiced character with an avatar, interruption handling, and desktop presence. What makes it interesting is the streaming interaction loop, not just the anime wrapper. Creators, consumer AI founders, and anyone testing more human-feeling interfaces should look.
Stars: 9,477 | Language: Python
