

The Push: June 2nd, 2026
Voice with texture, agents on a token diet, and OSINT that thinks in graphs


VoxCPM: Voices Became Design Material
github.com/OpenBMB/VoxCPM | License: Apache-2.0

A product demo used to need a designer, a script, a decent mic, and someone willing to record twenty takes without sounding dead inside. Then AI voice tools showed up, but the tradeoff was obvious: polished output, rigid feel. Synthetic voices still snapped back to the same polished, vaguely corporate center. VoxCPM goes after that gap with a bolder claim, speech should be generated, not assembled from pre-chopped audio units or squeezed through a brittle token vocabulary. That difference matters more than the hype cycle suggests.
The Drop: When TTS Stops Sounding Pre-Baked
Plenty of voice AI can read text. Far fewer can perform it. That is the frustration sitting underneath this repo.
Traditional text-to-speech systems often break speech into discrete units, then predict those units like language tokens. Efficient, yes. Also limiting. Human speech is full of tiny gradients, breathiness, rhythm changes, emotional drift, the half-second hesitation before a punchline lands. Once audio gets chopped into a compressed symbolic format, a lot of that nuance gets flattened or approximated. The result is the familiar uncanny zone, where the voice is clean but not convincing.
Voice Design and Controllable Cloning are OpenBMB’s answer to that. One creates a new voice from plain-language description alone. The other borrows a speaker’s timbre from a short clip, then lets you steer style separately, e.g. faster, warmer, more cheerful. Add Ultimate Cloning, which continues from a reference clip with transcript, and the target becomes obvious: not just “read this sentence,” but “continue this person.” That is a much harder, much more commercially useful problem.
The Stack: Big Model, Audio Native
Under the hood, VoxCPM is mostly Python and PyTorch, built on a MiniCPM backbone with custom speech modules for local encoding, diffusion-style generation, and audio reconstruction. The repo also pulls in Gradio for demos, LoRA tooling for fine-tuning, and serving hooks that work with accelerated runtimes like Nano-vLLM and vLLM-Omni.
The Sauce: Skipping Tokens, Keeping the Texture
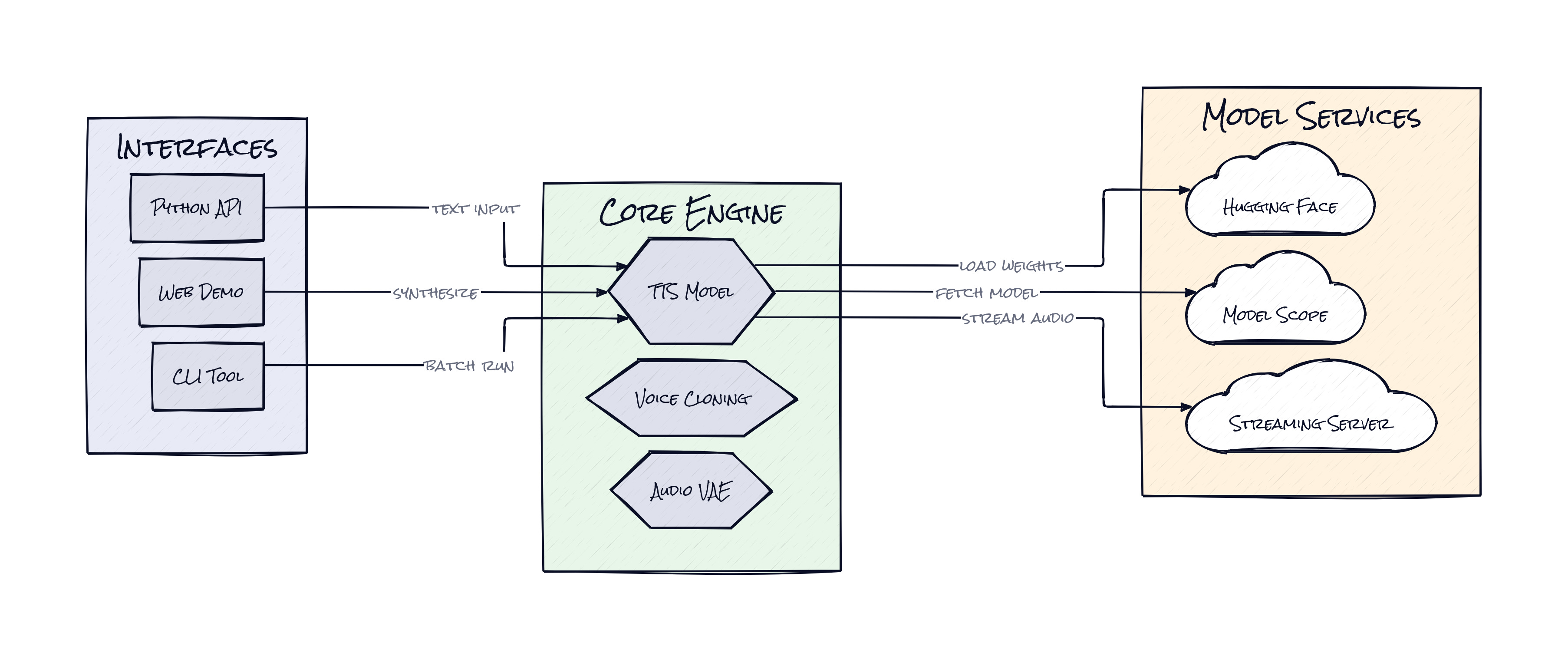
Tokenizer-Free TTS is the architectural bet worth paying attention to. VoxCPM does not first convert speech into a discrete audio vocabulary and then generate from those codes as if sound were just another text sequence. Instead, the model generates continuous speech representations directly through a Diffusion Autoregressive Architecture, then reconstructs high-fidelity output with AudioVAE V2.
That sounds academic, but the product consequence is pretty concrete. Discrete token pipelines are good at compactness and reuse. Continuous representations are better at preserving the messy, high-resolution details that make a voice feel embodied. VoxCPM is effectively saying that prosody, emotion, pacing, and timbre should live in the same generative space, not get split across separate hacks bolted on later.
Context-Aware Synthesis pushes that further. The model infers delivery from the text itself, instead of requiring heavy manual controls for every line. Then Real-Time Streaming makes the whole thing usable in actual products, because nobody wants a voice assistant that waits like a rendering farm. The smart part is not any single feature, honestly. It is the stack alignment. One architecture supports multilingual output, descriptive voice creation, style-steered cloning, and low-latency serving without feeling like four different products taped together.
That coherence is rare. A lot of AI voice repos are demos with edge cases. VoxCPM looks more like a platform thesis.
The Move: Turn Voice From Asset Into Interface
Brands, app teams, and AI product builders can use VoxCPM in three especially sharp ways. First, prototype a voice interface without negotiating with a closed vendor’s pricing, policies, or branding constraints. A startup building tutoring, wellness, gaming, or customer support flows can create distinct voices per use case and keep control of the stack. That alone changes the economics of experimentation.
Second, treat voice as a localization layer, not a final production bottleneck. VoxCPM supports 30 languages and does not require explicit language tags, which means global apps can test market-specific spoken UX much faster. Educational products, creator tools, and media workflows all benefit when multilingual narration stops being a separate procurement project.
Third, use fine-tuning and cloning strategically. Internal teams can adapt the model for a branded narrator, a recurring character, or a consistent assistant persona that lives across onboarding, support, and content. The advantage is not just cheaper audio generation. It is consistency. Once a company has a recognizable voice identity with low marginal cost, every new feature can speak in the same tone, literally.
The Aura: People Will Start Expecting Software to Sound Intentional
Apps used to have visual identity and little else. Voice changes that. Once synthetic speech gets expressive enough, users stop hearing it as output and start hearing it as presence. That raises the bar fast.
Products built with systems like VoxCPM can sound culturally local, emotionally appropriate, and brand-specific without a studio session every time copy changes. The deeper shift is behavioral: spoken software starts feeling less like accessibility garnish and more like a native interface layer. When that happens, silence becomes a product decision, not a default.
The Play: Open Voice Infrastructure Has Real Teeth
This looks less like a cute open source demo and more like a wedge into a large, already validated TAM spanning contact centers, creator tools, education, gaming, and AI companions. The category exists, but VoxCPM’s open weights, cloning controls, multilingual reach, and strong stars velocity suggest early PMF with developers and product teams who want quality without vendor lock-in.
Moat is mixed. Raw model access is not enough, and incumbents still own distribution, enterprise trust, and proprietary data. But open ecosystems can compound through execution speed, community fine-tunes, and lower CAC for startups building vertical voice products on top. Behavior change is sticky because once voice becomes part of the product surface, ripping it out hurts LTV, onboarding, and brand consistency.
Winners:
Hume AI: More emotionally aware voice apps get built on open infrastructure, which expands demand for higher-layer expression and evaluation products that compound with usage data.
Synthesia: Lower-cost, multilingual voice generation strengthens avatar video workflows where speech quality directly improves retention and enterprise expansion.
Spotify: Audio-native personalization gets cheaper to test across narration, translation, and creator tooling, which can increase engagement without waiting on studio-scale production.
Losers:
PlayHT: Margin pressure rises when high-quality cloning and voice design become accessible in open source, and differentiation based on basic synthesis gets thinner fast.
ElevenLabs: Pricing power weakens at the developer and prosumer edge as open alternatives get good enough for many production use cases, even if enterprise demand holds.
Adobe: Premium voice features inside creative suites look less defensible when standalone open models let creators build custom audio pipelines outside the bundle.
tl;dr
VoxCPM turns text, reference audio, or plain-language voice descriptions into high-quality multilingual speech, and the interesting part is its tokenizer-free architecture that keeps more of the texture traditional TTS flattens away. Worth a look for anyone building voice interfaces, media workflows, or branded AI assistants.
Stars: 25,005 | Language: Python
