

The Push: June 28th, 2026
GPU Python, video-to-3D memory tricks, and Mac dictation that actually keeps up


CuPy: GPUs Should Not Require Rewrites
github.com/cupy/cupy | License: MIT

Python data work has a familiar trap. A notebook feels fine on a sample dataset, then reality arrives, matrices get larger, simulations run longer, and suddenly every experiment turns into a coffee break. The annoying part is not that GPUs exist, everyone knows they do. The annoying part is the translation tax. One stack for easy numerical work, another for actual speed, plus enough glue code to make the whole thing brittle. CuPy matters because it treats that tax like a product failure, not a law of nature.
The Drop: When Fast Hardware Still Feels Inconvenient
Plenty of teams hit the same wall in different clothes. Quant researchers want larger backtests. Computer vision people need faster transforms before a model ever trains. Scientific computing teams already have years of NumPy and SciPy habits baked into notebooks, scripts, and internal tools. Then someone says, "just use the GPU," as if that phrase solves the migration problem.
What usually follows is ugly. A workflow that was readable becomes a patchwork of lower-level kernels, framework-specific rewrites, and hardware assumptions that make maintenance worse. Even when the speedup is real, the ergonomics can feel punishing. That is the gap CuPy goes after.
Rather than asking Python users to learn an entirely different mental model, CuPy offers a drop-in replacement approach for array computing on GPUs. Same broad array semantics, similar scientific APIs, much less code churn. Honestly, that framing undersells the pain it removes. The bottleneck in technical teams is often not raw compute access, it is the organizational friction of changing code that already kind of works.
The Stack: Python on Top, GPU Libraries Underneath
Under the hood, CuPy is Python backed by compiled GPU integrations for CUDA and experimental ROCm support. The project binds into NVIDIA math and acceleration libraries, e.g. cuBLAS, cuDNN, cuSPARSE, and cuSOLVER, while exposing array and scientific computing interfaces that mirror the familiar Python numerical stack.
The Sauce: Compatibility as an Architecture Choice
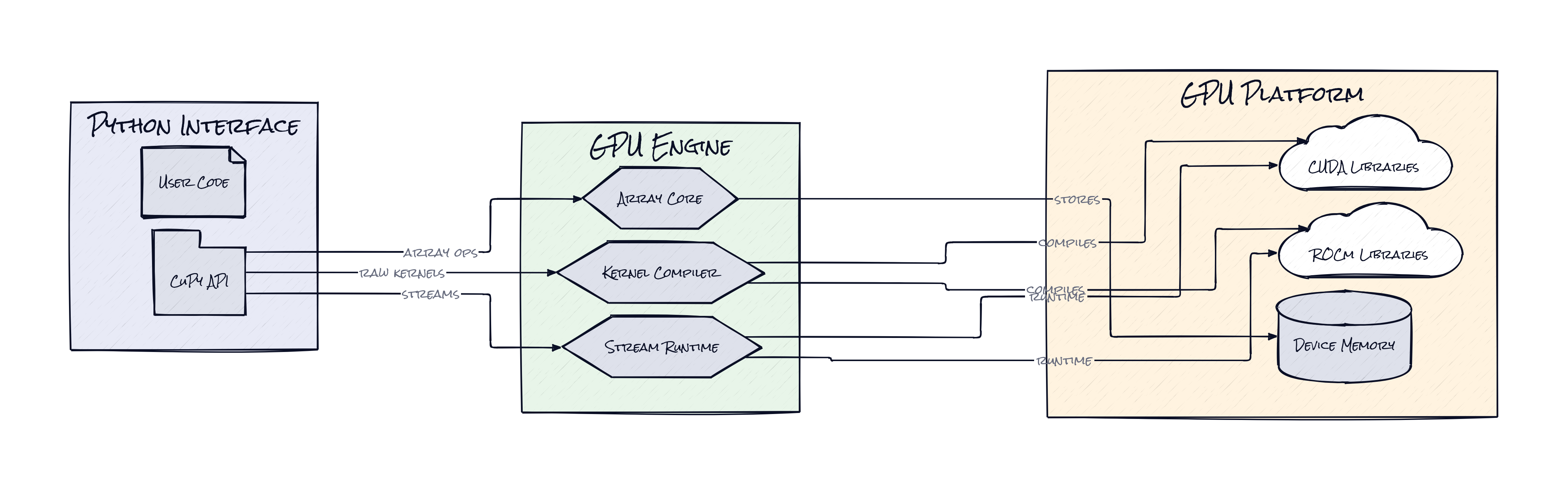
API compatibility is not a marketing wrapper here, it is the architecture. CuPy centers everything on a GPU-resident ndarray, which behaves enough like NumPy arrays that existing numerical code can often switch libraries with minimal surgery. That sounds straightforward, but the interesting part is how much surface area CuPy has to absorb to make that promise credible.
Behind the scenes, CuPy acts like a translation layer between Pythonic array operations and vendor-optimized GPU primitives. Dense linear algebra maps into acceleration libraries. Sparse operations route through specialized backends. Custom work can drop lower through RawKernels, giving users a path from high-level ergonomics to direct GPU execution without leaving the same ecosystem. That ladder matters. A lot.
Another sharp decision is CuPy's handling of runtime and backend variation. GPU software is a compatibility mess, and CuPy clearly knows it. The project carries abstractions for multiple vendor stacks, version quirks, and missing functions, effectively normalizing messy hardware realities into one user-facing array model. That is not glamorous, but it is exactly why the library has lasted.
Then there is Streams, which let computations and memory transfers overlap instead of waiting in a rigid line. For readers outside the weeds, that means better use of expensive hardware by coordinating work asynchronously. The result is not just "Python on GPU." CuPy becomes a portability layer for performance, where the core product decision is preserving developer habits while quietly orchestrating much harder systems work underneath.
The Move: Turn Existing Analysis Into GPU-Native Throughput
Instead of treating CuPy like a toy benchmark tool, the better move is to use it as a speed audit for any Python workflow already built around arrays. Start with the slowest notebook or batch job in research, analytics, simulation, or preprocessing. If the code already leans on NumPy-style operations, CuPy gives a realistic path to test GPU acceleration without funding a rewrite project first.
Founders building AI or scientific products should pay attention here. GPU budgets usually get discussed around model training and inference, but data preparation, signal processing, feature engineering, and optimization loops also eat serious time. CuPy can pull those adjacent workloads onto the same hardware footprint. That means fewer separate systems, faster iteration, and better asset utilization from GPUs already sitting in the stack.
Product teams can use that speed strategically. Shorter experiment cycles mean more parameter sweeps, more customer-specific simulations, or more responsive internal tooling. In practical terms, CuPy is valuable when a company wants the economic upside of accelerated computing without turning every quantitative workflow into a custom infrastructure project. That is the wedge.
The Aura: Performance Becomes a Default Expectation
Patience used to be part of numerical work. Run the job, wait, come back later, maybe tomorrow. CuPy chips away at that habit by making acceleration feel less like a specialized privilege and more like a reasonable default for people already working in Python.
That changes behavior. Analysts try more variants because the cost of being curious drops. Researchers keep workflows in one language longer, instead of escalating early to lower-level tooling. Teams start expecting interactive speed from tasks that used to belong to overnight compute. The deeper thesis is simple: when performance gets closer to familiar interfaces, ambition expands. People ask bigger questions because the machine stops arguing first.
The Play: Quiet Infrastructure, Huge TAM
From a VC lens, CuPy is not a 0-to-1 consumer category. It is a better mousetrap in a massive existing TAM, numerical computing, data science, scientific software, and AI-adjacent infrastructure. Still, better mousetraps matter when the wedge reduces migration cost so dramatically. The moat is not data or network effects, it is deep execution across compatibility, backend complexity, and trust earned from becoming a default layer in production and research workflows. More than 11,000 stars and years of sustained adoption signal real PMF, even if this is community infrastructure rather than a classic venture-scaled SaaS motion.
Winners:
Positron AI: Faster Python-native numerical workloads make inference and systems startups easier to benchmark, optimize, and compound without rebuilding every preprocessing stage from scratch.
Weights & Biases: Shorter experiment loops increase run volume and model iteration density, which tends to raise workflow stickiness and LTV inside existing ML teams.
NVIDIA: Broader access to GPU computing through familiar Python APIs expands demand for accelerator usage without requiring every user to become a CUDA specialist.
Losers:
Hex: Slower, CPU-bound collaborative analysis looks weaker when GPU-backed Python workflows can stay in familiar notebook patterns and finish materially sooner.
Dataiku: Visual analytics platforms lose some convenience advantage when technical teams can keep higher-performance experimentation inside code-centric workflows they already trust.
Intel: General-purpose CPU compute captures less incremental numerical workload when array-heavy Python jobs can jump to accelerators with much lower switching cost.
tl;dr
CuPy turns familiar NumPy and SciPy-style Python into GPU-accelerated computing with surprisingly little rewriting. The smart part is the compatibility architecture, a user-friendly array layer on top of messy vendor-specific GPU systems. Worth a look for AI teams, quants, researchers, and anyone whose Python workflows are hitting a performance ceiling.
Stars: 11,415 | Language: Python
