

The Push: June 1st, 2026
Shared AI memory, better taste for generated UI, and open models with fewer guardrails to trip over


Supermemory: Context Became Infrastructure
github.com/supermemoryai/supermemory | License: MIT

Chat with Claude on Monday, open Cursor on Wednesday, then ask a support bot something on Friday, and the same nonsense happens every time: the machine acts like the previous week never existed. Preferences vanish. Project details evaporate. Useful context gets repasted like a ritual. Supermemory lands on that exact pain point, but the interesting angle is not just “AI that remembers.” It is the bet that memory should be a shared service layer across apps, models, and workflows, not a cute feature trapped inside one chatbot.
The Drop: Your AI Keeps Starting Over
Anyone shipping AI products has run into the same ugly tradeoff. Either keep sessions stateless and accept dumb repetition, or bolt on a retrieval stack that quickly turns into a mini infra project. Suddenly you are managing embeddings, chunking, document sync, stale facts, and the deeply annoying question of what should be remembered versus what should be forgotten.
Supermemory exists because chat history alone is a terrible memory system. Conversations contain durable preferences, temporary tasks, contradictions, and external documents, all mixed together. A user might say they love dark mode, hate long meetings, switched jobs last month, and uploaded a product spec in the same hour. Treat all of that as one blob and recall gets noisy fast. Treat none of it as persistent and the assistant stays weirdly amnesiac.
That gap is bigger than consumer chat apps. Product teams building copilots, support agents, research assistants, or internal AI tools need something that can combine user profiles, RAG, and app-specific context without forcing every team to reinvent the same memory backend. Honestly, that backend has been missing in plain sight.
The Stack: Edge-Native, SDK-Heavy
Under the hood, Supermemory is mostly TypeScript, with a web app built around modern React tooling and an edge-first deployment footprint using Cloudflare services, Postgres, and Drizzle ORM. The repo also ships SDKs, browser extensions, and framework wrappers, which matters because distribution here is not just API access, it is presence inside the tools people already use.
The Sauce: One Memory Graph, Many Retrieval Paths
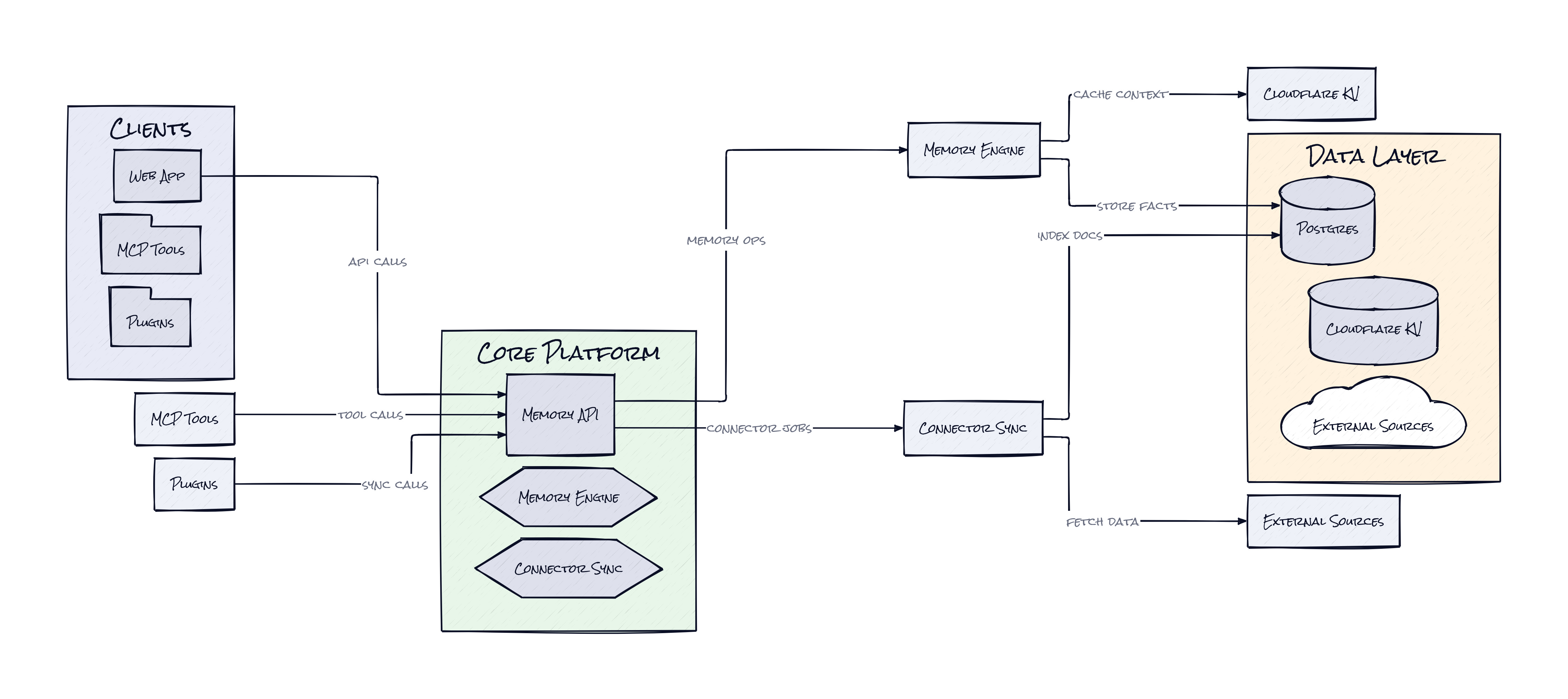
Supermemory’s core architectural choice is a single memory graph and ontology that stores personal facts, recent activity, synced documents, and extracted knowledge in one structure. That sounds subtle, but it fixes a major product problem: separate systems for “memory” and “knowledge base” usually create two competing truths. One query hits semantic search over documents, another hits conversation summaries, and the model gets stitched-together context with no shared logic for recency, contradiction, or relevance.
By keeping those inputs in one layer, Supermemory can offer hybrid search that returns both personalized recall and external knowledge in the same request. That is clever because users do not naturally separate “what the assistant knows about me” from “what the assistant knows for me.” They just ask a question. The system has to decide whether the answer lives in a stable preference, a recent conversation, a synced Notion page, or some combination.
The second smart move is user profiles as a first-class output, not just raw retrieval results. Search is reactive. Profiles are proactive. Instead of hoping the model asks the right retrieval query every turn, Supermemory maintains a compressed layer of stable and dynamic context that can be injected up front. That makes latency and prompt budget more predictable, and it gives builders a cleaner abstraction than endless vector search calls.
Then there is connectors, which pull in tools like Gmail, Drive, Notion, and GitHub with webhooks. That matters less as a checklist item and more as a freshness mechanism. Memory without updates becomes confidently wrong. Supermemory seems to understand that the hard part is not storing context, it is keeping context alive.
The Move: Turn Memory Into Product Surface Area
A founder building an AI copilot could use Supermemory to stop treating context as prompt glue and start treating it as product differentiation. Pipe every user conversation, uploaded file, and connected workspace into one scoped container, then let the app return profiles plus relevant knowledge in a single pass. That means onboarding gets shorter, repeat usage gets smarter, and the product starts feeling tailored without a giant custom infra effort.
Teams inside larger companies have an even clearer angle. Add persistent context to support bots, sales assistants, or internal search, and each interaction compounds instead of resetting. A support agent can remember account quirks and recent incidents. A research assistant can mix company docs with personal project history. A coding assistant can preserve preferences across IDEs, not just within one session.
The strategic advantage is retention through accumulated usefulness. Once an AI product remembers how someone works, switching away feels like losing trained context. That is a much stronger wedge than shipping yet another wrapper on top of the same model APIs.
The Aura: Expectation Inflation for Software
People are already changing their behavior around AI, repeating less, assuming more, and getting annoyed when the software forgets obvious things. Supermemory feeds that expectation. Once memory becomes ambient, users stop seeing context setup as part of the job and start seeing forgetfulness as product failure.
That changes the emotional contract with software. Assistants no longer feel like disposable query boxes. They start to feel like systems with continuity, which is powerful and slightly unsettling. The upside is obvious: less repetition, more momentum, better personalization. The deeper shift is that digital tools begin inheriting the social expectation humans already have, remember what matters, update when reality changes, and do not ask the same thing twice.
The Play: Owning the Memory Layer
This looks less like a pure 0-to-1 category creation and more like a sharp unbundling inside the AI application stack. TAM is broad because every agent, copilot, and enterprise assistant eventually runs into context persistence, but PMF depends on becoming the default memory substrate before platform vendors absorb the feature. The repo’s 23,875 stars, broad integrations, consumer app, and benchmark bragging rights are strong signals that Supermemory is not just a neat library, it is testing multiple distribution loops at once. The moat, if one forms, comes from ecosystem position and switching costs around accumulated context, not raw code defensibility.
Winners:
Delphi: Better long-term personalization compounds because digital clones and expert assistants live or die on continuity, and outsourcing memory infrastructure lets the team focus on persona and distribution.
Glean: Richer user-specific retrieval deepens enterprise relevance because workplace search gets better when company knowledge and individual context meet in one response surface.
Microsoft: Broader Copilot stickiness grows because cross-app memory can turn Office usage into a compounding context graph that is hard for rivals to match.
Losers:
Mem0: Narrower differentiation erodes because standalone memory APIs get squeezed when a rival ships stronger integrations, consumer touchpoints, and benchmark-driven credibility.
Perplexity: Session-level utility weakens because answer engines feel less personal when competing assistants remember ongoing goals, preferences, and documents across tools.
Salesforce: CRM-centric AI looks more constrained because memory-native assistants can assemble user context from many systems, while deeply structured enterprise software adapts more slowly.
tl;dr
Supermemory turns AI memory into a shared infrastructure layer, not a chatbot add-on. The clever part is one unified memory graph that can serve profiles, retrieval, and synced external knowledge together. Worth a look for anyone building AI products where repeat interactions, personalization, and cross-tool context actually matter.
Stars: 23,875 | Language: TypeScript
