

The Push: June 19th, 2026
Forecasting brains, codebase memory, and AI timeline control for teams wrangling messy data, sprawling repos, and video workflows


TimesFM: Forecasting Escapes the Spreadsheet Trap
github.com/google-research/timesfm | License: Apache-2.0

A revenue dashboard dips for three weeks, then rebounds. Is that seasonality, a promo effect, or the start of a real slowdown? Plenty of teams still answer that question with a spreadsheet, a gut check, and maybe one data scientist stuck rebuilding the same forecasting pipeline again. TimesFM lands right on that pain. It takes the foundation model idea, pretraining across huge amounts of time series data, and points it at forecasting, a category that has stayed oddly fragmented despite being everywhere in business.
The Drop: Prediction Needed a Shared Model
Forecasting has always had an annoying asymmetry. Every company cares about demand, churn, traffic, sales, inventory, energy load, or usage spikes, but building decent prediction systems still tends to require custom modeling, hand-tuned features, and domain-specific cleanup. Even when the math works, the workflow often does not. One team runs ARIMA, another tries gradient boosting, a third wires together a deep learning stack that nobody wants to maintain six months later.
Google’s bet here is that time series should get the same treatment language and vision got: one pretrained model that already understands broad statistical patterns before touching your data. That matters because real-world sequences are messy. They have missing values, changing scales, weird periodicity, sudden shocks, and limited history. Traditional tools usually need explicit assumptions about those behaviors. Time Series Foundation Model means the assumptions are absorbed into pretraining instead.
Honestly, that is the gap. Not “forecasting exists,” everyone knows that. The gap is that usable forecasting has been too bespoke for how universal the need is.
The Stack: Transformer, but Pointed at Sequences
Under the hood, TimesFM is a decoder-only forecasting model built in Python, with support for both PyTorch and Flax. The repo wraps pretrained checkpoints from Hugging Face, uses JAX for fast inference on one path, and adds optional XReg support for external covariates, e.g. promotions or calendar signals.
The Sauce: Why Tokenizing Time Is the Whole Bet
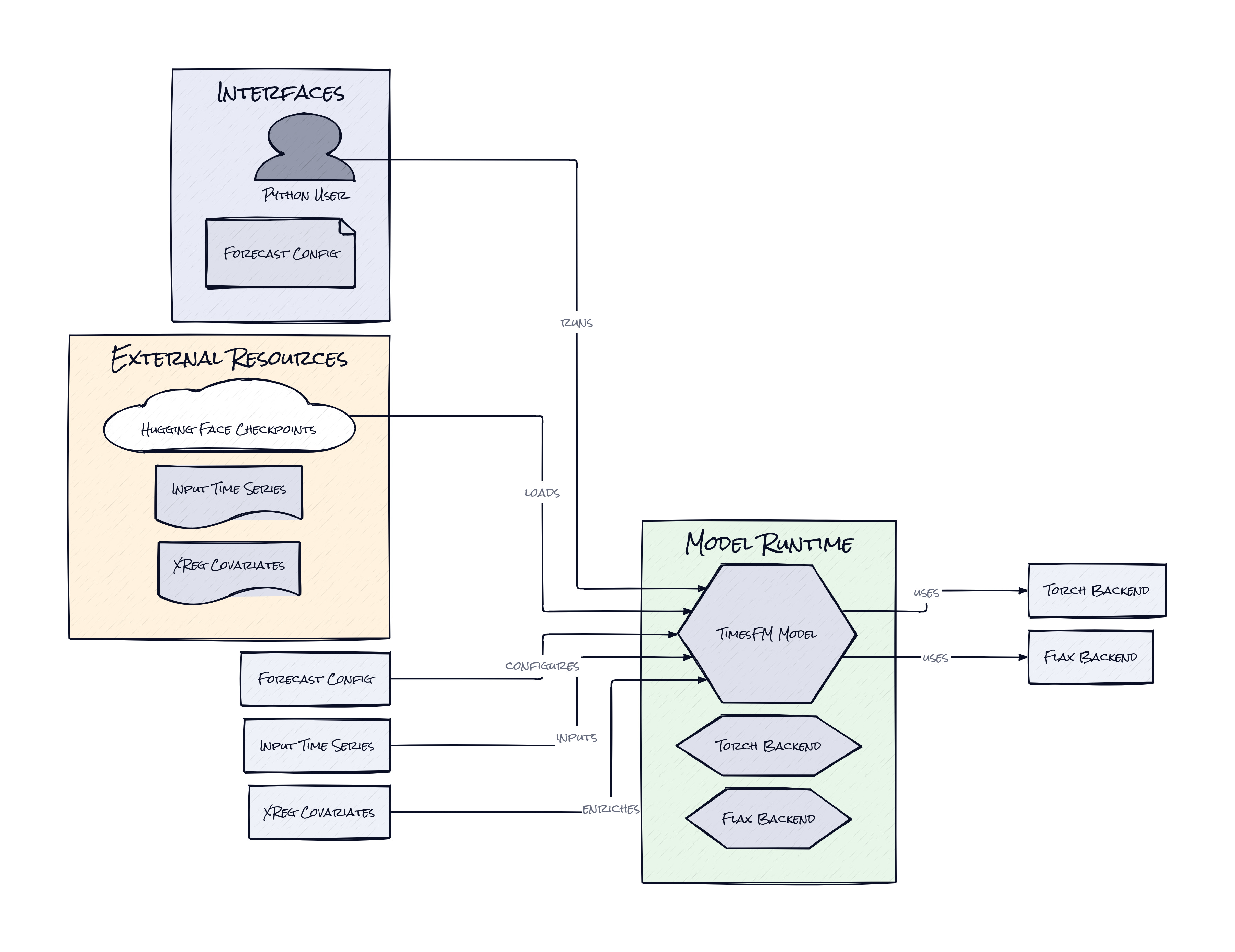
Instead of treating every forecasting problem as a fresh statistical exercise, TimesFM turns numeric history into a shared model interface. The architecture chunks series into patches, runs them through a transformer stack, and predicts future patches autoregressively. That sounds familiar if you have followed LLMs, but the interesting part is how the repo adapts that pattern to ugly business data.
One key choice is RevIN, short for reversible instance normalization. Before prediction, each series gets normalized by its own running mean and variance, then the transform is reversed after decoding. That matters because a power grid, an ad campaign, and an ecommerce category can live on completely different numeric scales. RevIN lets one model reason over pattern shape without getting confused by raw magnitude. Subtle, but very effective.
Another smart layer is continuous quantile head support. Forecasts are not just single-line guesses, they can output probability bands across future horizons. For planning, that is the difference between “sales might be 10,000” and “there is a 10 percent chance demand blows past inventory.” The latter is how operators actually make decisions.
Then there is XReg, which brings covariates back into the picture. Pretrained sequence understanding is strong, but demand often moves because of something outside the series itself, e.g. price changes, holidays, or campaigns. XReg keeps the base model general while giving teams a place to inject business context. That separation is clever because it preserves the broad pretrained prior without pretending every forecast is self-contained.
The Move: From Analytics Ornament to Operating Input
Plenty of teams could use TimesFM without turning into an ML lab. Product and ops groups can pipe historical metrics into the model and get baseline forecasts for planning headcount, budgeting cloud spend, spotting anomalies, or stress-testing launches. Connected Sheets and BigQuery integrations in Google’s wider ecosystem hint at the obvious destination: forecasting as a default layer inside tools people already use.
Founders and PMs should notice the strategic angle. A generic forecast API changes how quickly a company can operationalize uncertainty. Instead of waiting for a custom model build, teams can test scenarios early, compare predicted versus actual outcomes, and decide where bespoke modeling is actually worth the effort. That shrinks the cost of experimentation.
Start with one metric that already drives money or risk, e.g. subscription renewals, delivery volume, or customer support load. Run TimesFM as the baseline. Then add covariates and compare uplift. If the pretrained model gets close enough, the advantage is not just accuracy. The advantage is speed, consistency, and fewer analytics bottlenecks across the org.
The Aura: Software Starts Having Expectations
Planning changes when prediction stops being a specialist ritual. Teams begin expecting every metric to come with a likely future, a confidence range, and an explanation of what is driving variance. That expectation is huge. It means dashboards become less archival and more anticipatory.
TimesFM also pushes a quiet philosophical point: not every valuable AI system needs to talk. Some of the highest-leverage models will sit behind operational decisions, shaping staffing, inventory, pricing, and spend. Humans still choose, but the default posture shifts from reacting to numbers toward managing probabilities.
The Play: Foundation Models Come for Forecasting
This looks less like a pure 0-to-1 category and more like a serious platform wedge into a large, sleepy market. Forecasting TAM is broad because it cuts across retail, finance, logistics, energy, SaaS, and manufacturing, but PMF will depend on whether pretrained accuracy plus low setup beats custom pipelines on total cost and speed. Nearly 24,000 stars, active updates, fine-tuning examples, and ecosystem placement inside Google products are solid signals that this is not just paperware.
Moat is mixed. Open source weakens model exclusivity, so defensibility probably comes from distribution, workflow embedding, and proprietary data loops layered on top. Sticky behavior change seems real if teams start wiring forecast outputs into planning cycles, because once a prediction system touches budgets and operations, switching costs rise fast.
Winners:
Pocus: Faster revenue forecasting and pipeline risk scoring become more credible product surfaces, which compounds through better PMF with go-to-market teams.
Samsara: Better demand and fleet usage prediction can deepen operational value for customers, lifting LTV without a huge CAC reset.
Google: Embedded forecasting inside BigQuery, Sheets, and Vertex strengthens cross-product lock-in, turning a research repo into distribution fuel.
Losers:
Akkio: General no-code predictive tooling gets pressured when foundation-model forecasting becomes cheap enough to bundle into broader data stacks.
DataRobot: Enterprise AutoML loses some premium when baseline time-series performance is available from a pretrained open model with faster time-to-value.
IBM: Consulting-heavy forecasting workflows look slower and more expensive when teams can ship competent predictions straight from modern cloud analytics surfaces.
tl;dr
TimesFM turns pretrained transformers into a forecasting engine for messy business time series. The clever part is not just using a big model, it is the normalization, uncertainty bands, and covariate design that make one model usable across wildly different signals. Product, ops, and data teams should look.
Stars: 23,979 | Language: Python
