

The Push: July 1st, 2026
Messy PDFs, AI trading guardrails, and editable design systems for teams shipping with humans and copilots


Olmoocr: PDFs Need a Reading Brain
github.com/allenai/olmocr | License: Apache-2.0

A PDF should be the easiest file in the world to feed into AI. Instead, it routinely turns into broken columns, repeated headers, mangled tables, and equations that read like static. That matters more than people admit, because a huge share of the world’s serious knowledge still lives inside papers, scans, reports, and filings. Olmoocr goes after that bottleneck with a blunt premise: if language models are only as good as their inputs, document extraction is not a boring preprocessing step. It is core model infrastructure.
The Drop: Where Smart Documents Go Dumb
Anyone who has tried to build a research assistant, a compliance copilot, or even a decent internal search tool has hit the same wall. The source material looks fine to humans, then collapses once a machine touches it. Multi-column academic PDFs get read in the wrong order. Footers repeat every page and quietly pollute embeddings. Tables flatten into nonsense. Math disappears. Scanned documents become a blur of almost-right text.
Classic OCR was built to recognize characters. That sounds useful until the actual task is reconstructing a document’s meaningful sequence. A paper is not just symbols on a page, it is layout, hierarchy, reading order, exclusions, and formatting cues that tell an LLM what belongs together. That gap is what drove Olmoocr.
AllenAI is clearly optimizing for people who need clean corpora at scale, not just pretty one-off conversions. The repo description says “linearizing PDFs for LLM datasets/training,” and that word, linearizing, is the whole point. The frustration is not that PDFs are hard to read. The frustration is that machines keep reading them wrong.
The Stack: Vision Models, Not Regex Therapy
Under the hood, Olmoocr is a Python pipeline built around a vision language model, with vLLM handling inference and PyTorch powering local GPU runs. The system also leans on PDF rendering tools, image processing, and cloud storage hooks, then outputs clean Markdown or structured dataset-ready text instead of raw OCR blobs.
The Sauce: Linearization as the Product
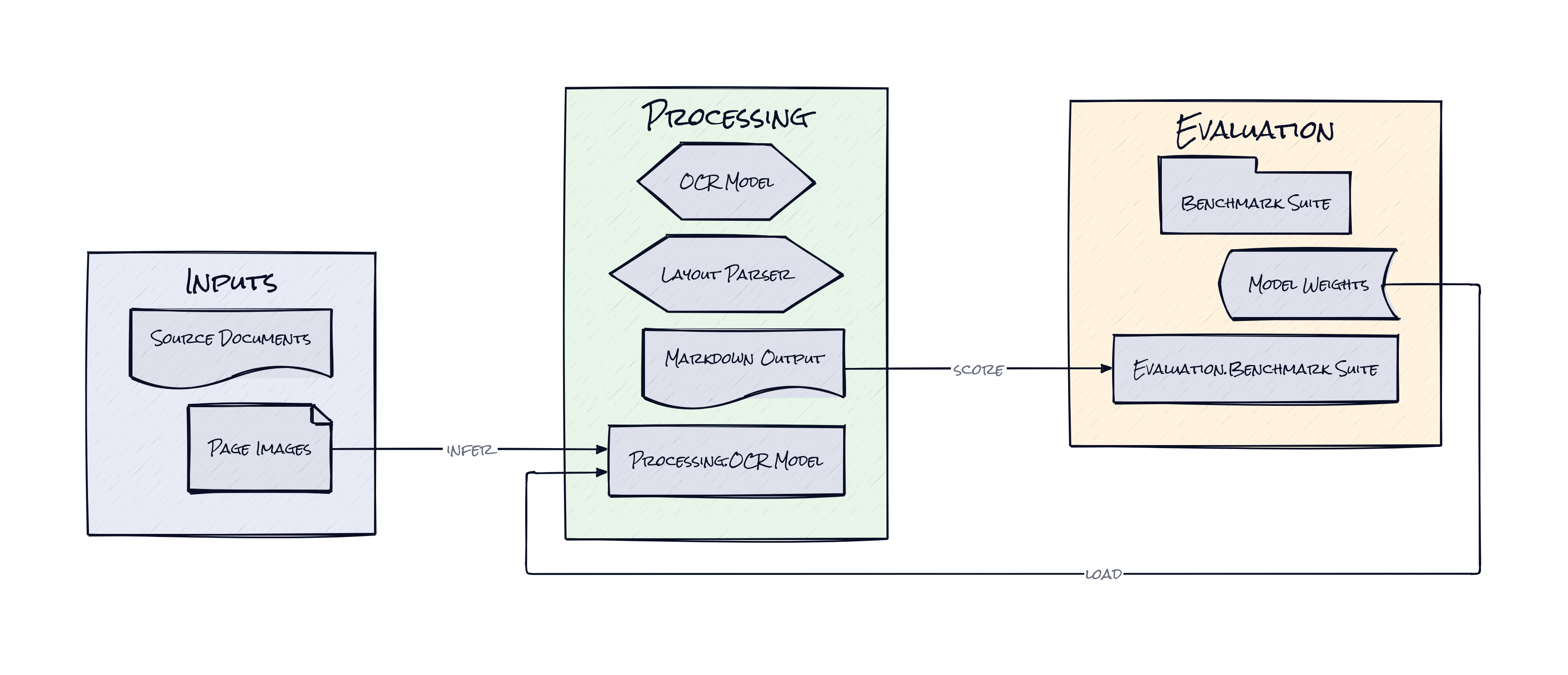
Plenty of OCR tools can extract text. OlmOCR-Bench is what makes this repo more than another parser, a purpose-built evaluation suite that tests whether output preserves things humans actually care about, e.g. reading order, header removal, math fidelity, table structure, and multi-column flow. That choice matters because optimizing OCR for token-level accuracy often misses the bigger failure, a document that is technically recognized but semantically unusable.
Olmoocr’s architecture seems built around page understanding as a model inference problem, not a stack of brittle layout heuristics. Pages get rendered as images, fed through a VLM, and translated into Markdown in a natural sequence. That lets the model reason over equations, figures, handwriting, and weird formatting in one pass, instead of handing off each edge case to a separate subsystem. Honestly, the interesting part is not “AI does OCR.” It is that the repo treats document conversion as structured generation with constraints.
There is also a strong systems angle. The pipeline supports local GPU inference, remote inference servers, batch processing, and cloud object storage, which tells a more important story than the demo does. This was designed for throughput. The benchmark, retry logic, and fallbacks all point to a team that cares about turning messy archives into dependable training data.
That is clever because the value is not just better extraction. The value is trustworthy document-to-text infrastructure that can be measured, tuned, and run at industrial scale.
The Move: Turn PDFs Into Proprietary Data Pipes
Founders and product teams should read Olmoocr less as an OCR utility and more as a data acquisition engine. Any company sitting on PDFs, contracts, manuals, scientific papers, invoices, or regulatory filings can use this to create a cleaner text layer for search, retrieval, fine-tuning, or analytics. That changes the economics of “dark data,” the information already owned but not actually computable.
Research startups can ingest arXiv-style corpora without poisoning downstream models with repeated headers and broken equations. Legal and finance teams can normalize filings into Markdown, then feed them into internal copilots with much better chunk quality. Enterprise AI vendors can run a private conversion stack rather than shipping sensitive documents to an API.
Strategically, the win is not just lower OCR cost. The win is better downstream model behavior. Cleaner reading order means better retrieval. Better table parsing means stronger analytics. Cleaner markdown means less manual curation before training. Every product promising document intelligence ends up competing on this layer whether it admits it or not.
Olmoocr gives teams a chance to own that layer, benchmark it, and tune it around their own document mix. That is a real edge.
The Aura: Machines Start Reading Like Adults
People are going to expect software to understand documents the way a sharp analyst does, not the way a scanner does. That expectation changes behavior. Instead of manually cleaning reports before sharing them with an AI tool, teams will start assuming raw files are already usable. Instead of treating PDFs as final artifacts, companies will treat them as live inputs to search, analysis, and model training.
Olmoocr points at a quieter shift than flashy chat apps. The frontier is not always better answers, sometimes it is better source material. Once machines can read dense documents with fewer distortions, human attention moves up a layer, away from cleanup and toward judgment.
The Play: The Unsexy Layer With Real Budget
This looks more like a better mousetrap than a pure 0-to-1 category creation, but the market is big enough that “better” can still be venture-scale. TAM spans enterprise document AI, legal tech, research tooling, and model training pipelines. The PMF signal is strong for an infrastructure repo, 18,176 stars in under a year, active releases, a public benchmark, and clear community pull around cost and quality. The moat is not classic network effects. It is benchmark credibility, hard-won document edge cases, and execution speed on a nasty problem that sits directly upstream of LTV for every document-heavy AI product.
Winners:
Hebbia: Cleaner ingestion of complex reports and filings compounds into better answer quality, which raises trust and lowers analyst workflow friction.
Harvey: Stronger document linearization improves legal retrieval and drafting accuracy, which directly supports enterprise expansion and seat growth.
Thomson Reuters: Better open document parsing reduces dependence on manual structuring and strengthens existing data products with lower marginal content prep cost.
Losers:
Danswer: Generic enterprise search loses ground when document quality becomes a differentiated ingestion layer and customers demand deeper parsing control.
Ironclad: Workflow advantages erode if upstream contract understanding gets cheaper and more portable across broader AI stacks.
Adobe: Premium document workflows look softer when open infrastructure increasingly handles extraction, normalization, and downstream AI readiness outside the PDF authoring bundle.
tl;dr
Olmoocr turns ugly PDFs, scans, and image documents into clean Markdown that LLMs can actually use. What stands out is the focus on linearization and benchmarking, not just text extraction. Anyone building search, research, legal, or training-data products on top of dense documents should pay attention.
Stars: 18,176 | Language: Python
