

The Push: April 23rd, 2026
Three clever hacks: an ML lab assistant, a searchable security toolbox, and a model-agnostic coding shell


Ml Intern: The ML PM Nobody Hired
github.com/huggingface/ml-intern

Hours disappear fast when an ML project starts with one innocent sentence, e.g. “fine-tune a model on this dataset.” First comes paper hunting, then repo spelunking, then dataset inspection, then cloud setup, then another round of “why does this script even save checkpoints there?” Ml Intern goes after that exact mess. Not the chatbot fantasy version of AI work, the actual glue work that turns a promising idea into a shipped model. Honestly, that’s a much more interesting target than yet another code assistant.
The Drop: ML Work Has Too Many Tabs
Anyone who has watched a model project up close knows the bottleneck usually is not “coming up with an idea.” The bottleneck is stitching together six different systems that were never designed to feel like one product. Papers live in one place, datasets in another, training jobs somewhere else, docs everywhere, code examples buried in old repos, and the final deployment path hidden behind platform-specific rituals.
Ml Intern exists because ML engineering still feels like a scavenger hunt. A human has to read the paper, check whether the dataset is usable, inspect schema quirks, find a relevant model, write training code, launch compute, approve risky actions, and keep enough context in memory to not lose the thread halfway through. That is a lot of state to juggle.
Hugging Face clearly saw the gap: generic coding agents can write Python, but they usually lack situational access to the actual ML ecosystem. Without direct hooks into papers, datasets, repos, docs, and jobs, an “AI engineer” is mostly guessing. That guessiness is expensive.
The Stack: Python Wiring, Web Shell, Model Agnostic Core
Under the hood, Ml Intern is mostly Python, with a FastAPI backend, a React frontend, and LiteLLM handling model calls so the system is not locked to one provider. Hugging Face services are first-class dependencies, and the agent can also talk to external tools through MCP servers, which effectively extend its reach without hardcoding every integration.
The Sauce: A Vertical Agent, Not a Generic One
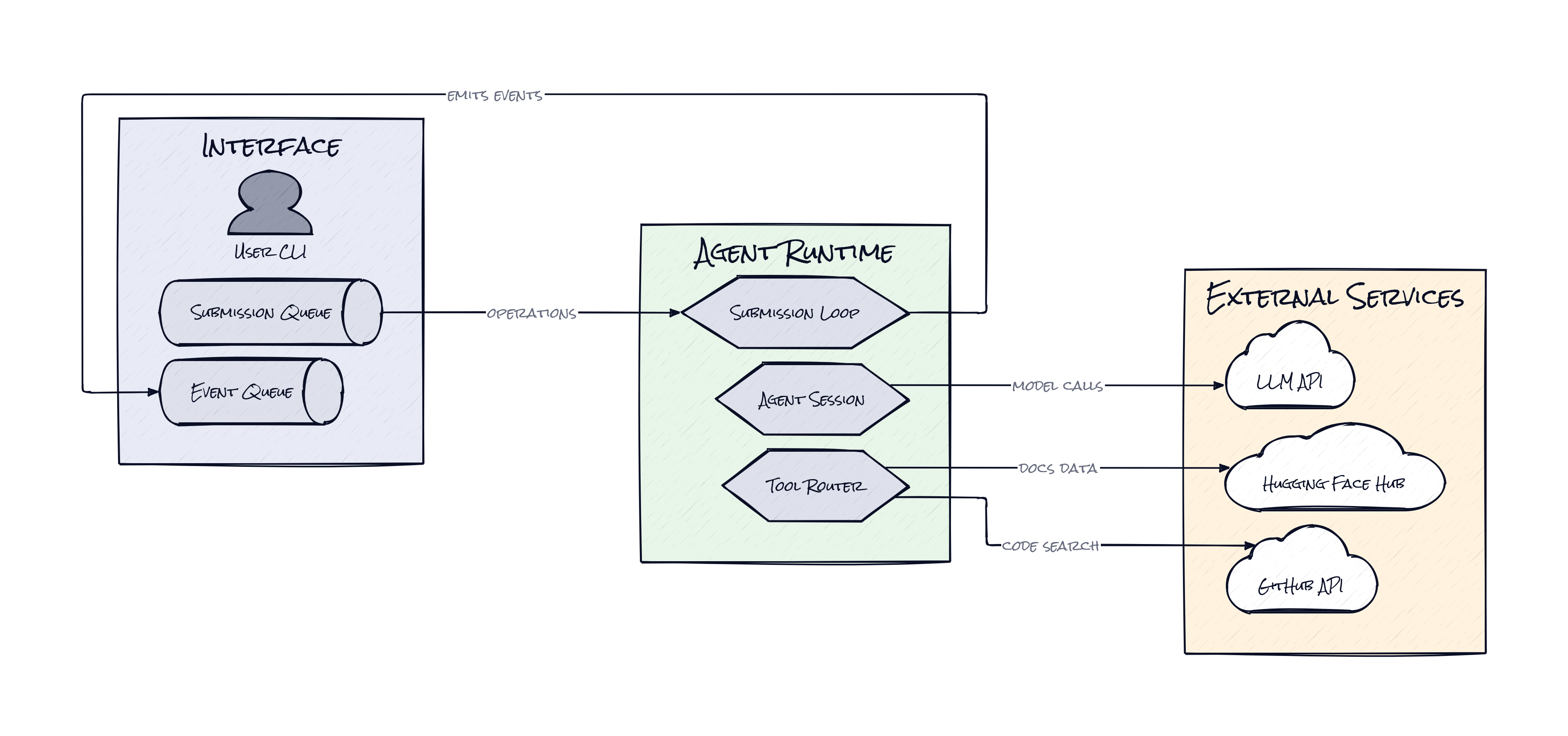
What makes Ml Intern interesting is the ToolRouter, a routing layer that gives the model a curated map of ML-native actions instead of a random bag of tools. That sounds subtle, but it changes the product from “LLM with permissions” into a workflow engine aimed at one job: getting machine learning work across the line.
Within a single session, the model can inspect datasets, search GitHub for examples, read docs and papers, browse Hugging Face repos, spin up sandboxed work, and submit cloud jobs. The architecture keeps all of that tied together through a ContextManager, which stores message history, compacts context when conversations get too large, and uploads sessions back to Hugging Face so work does not evaporate between turns. That compaction piece matters more than it sounds. Long-running agent sessions usually fail not because the model is dumb, but because they become bloated and lose the plot.
Another sharp choice is the Doom Loop Detector. Agents love repeating failed tool patterns, especially when a task spans research, code generation, and execution. Ml Intern watches for that behavior and injects corrective prompts before the system burns tokens in circles. Add the approval layer for risky actions like compute jobs and uploads, plus streaming event updates for every tool call and response, and the result feels less like a demo and more like a supervised junior teammate. That is the clever bit: autonomy, but with enough structure to keep it useful.
The Move: Turn Research Friction Into Shipping Speed
Product teams, applied researchers, and startup founders could use Ml Intern as a force multiplier at the exact point where ML projects usually stall. Feed it a goal like evaluating an open model on a domain dataset, and the system can gather papers, inspect dataset structure, locate implementation patterns, draft training code, and prepare jobs without someone manually bouncing between browser tabs for an afternoon.
Founders especially get a strategic edge here. Instead of hiring immediately for every exploratory ML task, a lean team can test feasibility faster, validate whether a dataset is actually trainable, and get to first model output before spending on a full stack of specialized talent. That shortens the path from hypothesis to evidence.
Research teams could also use Ml Intern as a reproducibility assistant. Ask for a paper implementation, compare available datasets, and have the system organize the boring but essential setup work. The benefit is not full automation. The benefit is compressing the overhead around expert judgment, so humans spend time deciding what matters, not hunting for where the docs or training examples live.
The Aura: Expectations Rise Once the Glue Gets Automated
People tolerate a shocking amount of tool switching in ML because the field has trained everyone to expect friction. Search here, copy there, rerun this, sanity-check that, then hope the cloud job did what the config implied. Ml Intern nudges a different expectation: maybe the orchestration layer should be conversational, stateful, and domain-aware.
That changes behavior. Instead of treating ML work as a sequence of fragile handoffs, teams can start treating it like an ongoing dialogue with a system that knows the ecosystem and remembers the assignment. The deeper implication is psychological: expertise becomes less about navigating interfaces, more about making better calls.
The Play: Vertical Agent PMF Beats Horizontal Hype
From a VC lens, Ml Intern looks less like a 0-to-1 market creation and more like a sharp wedge into the massive ML tooling TAM. The repo is early, but 2,456 stars for a narrowly scoped open source ML engineer is a decent signal that the pain is real, not manufactured. PMF is not proven, but the engagement pattern suggests demand for vertical agents that own an end-to-end job, not just one screen in the workflow.
The moat probably is not core model tech. It is distribution through the Hugging Face ecosystem, tight integration with datasets, papers, repos, and jobs, plus the execution speed to keep expanding the agent’s usable surface area. If behavior changes from “open five tabs” to “delegate the setup loop,” stickiness gets strong fast, CAC can stay low through open source, and LTV rises with every adjacent ML task the system absorbs.
Winners:
Lamini: Faster prototyping cycles get cheaper, which compounds for a startup selling enterprise paths to custom model deployment.
Hugging Face: Deeper workflow capture around training and shipping models strengthens platform gravity beyond being just the place models live.
Snowflake: More teams operationalizing ML experiments increases demand for governed data infrastructure that can feed those pipelines.
Losers:
Aixplain: Generic AI orchestration loses edge when buyers start preferring domain-specific agents with native ML context.
Scale AI: Manual services-heavy model development gets pressured as more of the setup and experimentation loop becomes software.
Upwork: Small freelance ML glue tasks erode first, because this is exactly the kind of fragmented work an agent can increasingly absorb.
tl;dr
Ml Intern turns ML engineering busywork into a supervised agent workflow that can read papers, inspect datasets, write training code, and launch jobs inside the Hugging Face universe. The smart part is the architecture, especially its routed tool access, context compaction, and loop control. Worth watching for startups, research teams, and anyone trying to ship ML with fewer coordination headaches.
Stars: 2,456 | Language: Python
