

The Push: April 21st, 2026
Multimodal doc brains, repo-scale AI context, and a more obedient YouTube app


RAG Anything: PDFs Finally Stop Acting Flat
github.com/HKUDS/RAG-Anything | License: MIT

A quarterly report lands in the inbox. Half the insight sits in charts, buried tables, equation-heavy footnotes, and annotated screenshots. Standard RAG happily grabs the body text, then answers with suspicious confidence while ignoring the evidence that actually mattered. That gap is where RAG Anything gets interesting. This repo treats documents less like blobs of text and more like structured, mixed-media knowledge assets. Honestly, that sounds obvious. In practice, plenty of AI stacks still pretend every file is just markdown wearing a nicer outfit.
The Drop: When Retrieval Misses the Important Part
Anyone building AI on top of enterprise documents eventually hits the same wall: the answer is technically in the file, but not in the part the system can meaningfully read. A policy PDF has a key exception tucked inside a table. A research paper explains the result in prose but proves it in an equation. A board deck hides the real story in one chart with three tiny labels. Traditional retrieval pipelines were built for paragraphs, not interleaved content.
RAG Anything exists because document intelligence got fragmented. One tool parses PDFs. Another handles OCR. Another tries table extraction. Another adds image understanding. Then somebody glues together embeddings, metadata, and prompts and hopes context survives the trip. It usually doesn’t. Relationships between text, visuals, and structure get lost right when they matter most.
That frustration shows up everywhere, from legal review to financial analysis to academic search. The repo’s bet is simple: multimodal retrieval should be a single system problem, not a pile of adapters pretending to be a product.
The Stack: Python Glue, Vision Included
Under the hood, RAG Anything is a Python framework built on LightRAG, with document parsing support tied into MinerU and optional model integrations through OpenAI-style, Ollama, LM Studio, and vLLM back ends. The architecture also exposes parser registration, batch processing, and resilience layers, which matters because multimodal pipelines break in annoyingly many places.
The Sauce: A Knowledge Graph That Sees More Than Text
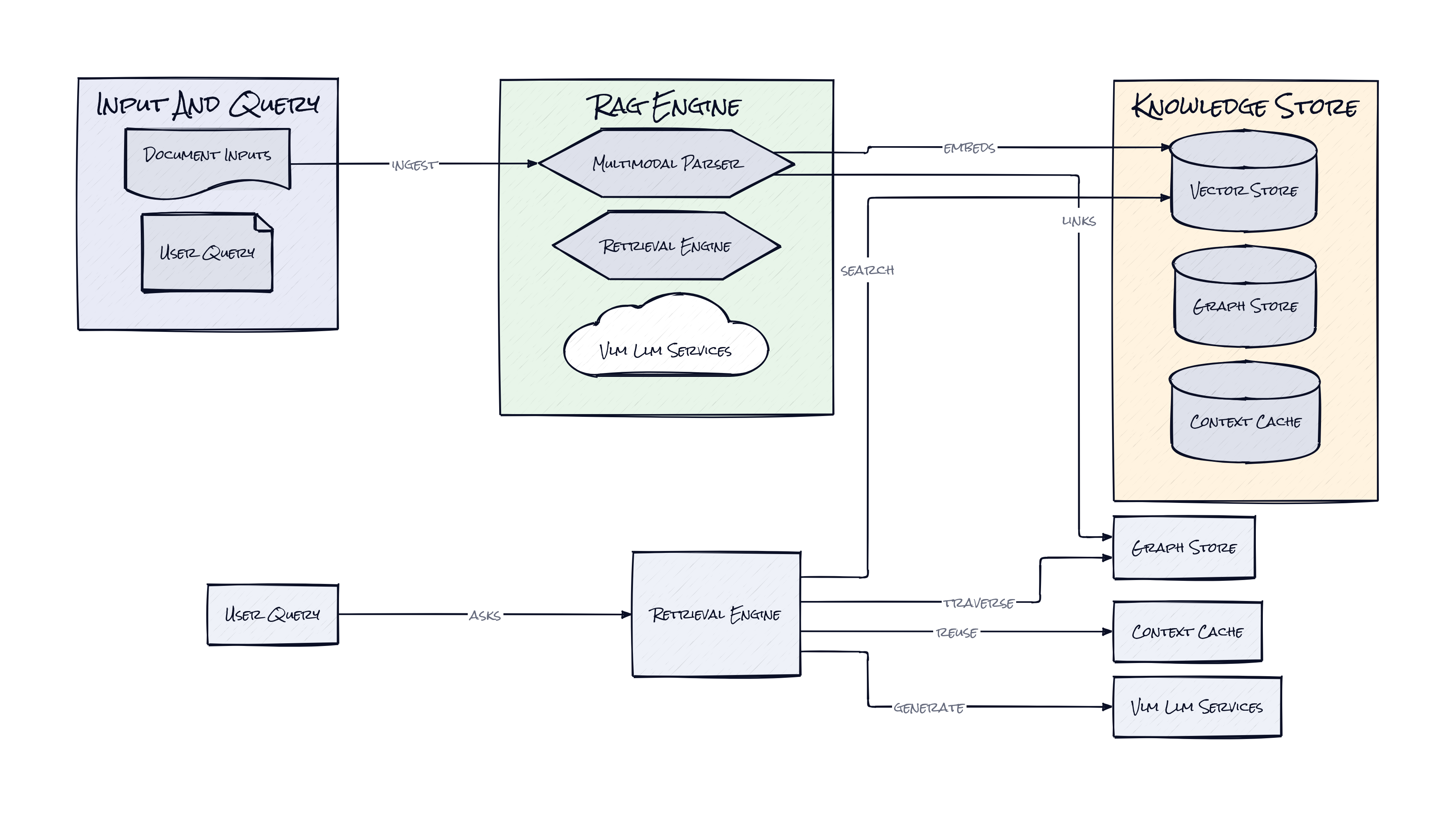
Across the repo, the standout choice is the Multimodal Knowledge Graph, which turns parsed document elements into linked entities and relationships instead of tossing everything into one embedding soup. That sounds academic, but it solves a very practical problem: a chart caption, a nearby paragraph, and a table value often mean more together than separately. Vector search alone is bad at preserving that kind of cross-modal dependency.
RAG Anything processes documents as decomposed content units, then connects them through structural and semantic relationships. Text chunks still matter, but images, tables, and equations become first-class citizens in retrieval rather than attachments the model sees only at answer time. That architecture lets the system retrieve not just “the paragraph about revenue growth” but the neighboring chart, the table row behind the claim, and the contextual links that explain why those pieces belong together.
Another smart move is the repo’s Direct Content List Insertion path. Instead of forcing every workflow through one parser, RAG Anything can ingest pre-structured content from external systems. That makes the framework more like an orchestration layer than a monolith. Teams with existing OCR, ETL, or document pipelines can plug in upstream outputs without rebuilding everything.
Then there’s VLM-Enhanced Query, which routes image-bearing context into vision-language analysis during question time. That matters because retrieval quality is only half the battle. If the model cannot reason over the visual evidence it fetched, the stack still collapses. The interesting part is the end-to-end coherence: parse multimodal content, model relationships explicitly, then query with components that can actually read what was retrieved.
The Move: Turn Messy Documents Into Defensible Answers
Plenty of teams could use RAG Anything as the backbone for internal search, but the sharper play is building domain-specific copilots where source fidelity matters. A fund could index earnings decks, filings, and analyst PDFs, then ask questions that require both text and tables. A legal ops team could search contracts where clauses, signatures, and scanned exhibits all carry meaning. A research startup could build literature review tools that do not fall apart when equations and figures show up.
Because RAG Anything accepts mixed inputs and even pre-parsed content, it fits neatly into companies already sitting on document exhaust. Product advantage comes from answering harder questions with fewer hallucinations, and from being able to cite the right evidence, not just nearby words. That changes trust.
Founders should notice another angle: this repo lowers the cost of shipping “multimodal RAG” as an actual feature instead of a vague roadmap promise. If a workflow depends on PDFs, spreadsheets, diagrams, or slideware, RAG Anything can compress months of pipeline assembly into something testable fast.
The Aura: Software Starts Reading Like People Do
Nobody reads a dense report linearly anymore. Eyes jump from summary to chart to footnote to table, stitching meaning from different forms at once. RAG Anything bakes that behavior into the retrieval layer. The result is not just better answers, it is software that seems to respect how information is actually consumed.
That raises the bar for AI products. Once systems can reference visual evidence, structured values, and surrounding prose together, users stop tolerating text-only shortcuts. Expectations shift from “good enough summary” to “show the exact support.” In knowledge work, that changes confidence more than raw speed ever did.
The Play: Infra Pick in a Crowded RAG Market
RAG Anything is not a pure 0-to-1 category creation. The market already knows RAG, enterprise search, and document AI. The opportunity is closer to a better mousetrap with expanding TAM, because multimodal enterprise knowledge remains badly served and every serious AI app eventually runs into non-text documents. The repo’s 16,653 stars, rapid community uptake, and visible examples across batch, parser, and model integrations are early PMF signals for developer mindshare. The moat is probably not proprietary data yet. It looks more like execution speed, ecosystem fit, and workflow stickiness once a company’s document graph becomes part of daily operations.
Winners:
Unstructured: Faster adoption compounds because better ingestion of messy enterprise files feeds directly into downstream AI products and raises LTV across existing customers.
Hebbia: Higher-quality multimodal retrieval strengthens the pitch for deep research workflows where trust, citation, and cross-document reasoning justify premium CAC.
Microsoft: Richer document understanding inside Copilot and Azure AI makes the platform more defensible for enterprise knowledge work already anchored to Office files.
Losers:
Rivet AI: Narrow text-centric workflow tooling erodes when baseline expectations shift toward native handling of charts, tables, and image-heavy documents.
Glean: Search differentiation weakens if open multimodal retrieval stacks make “find the answer inside enterprise docs” less proprietary and easier to replicate.
Adobe: Standalone document intelligence value gets pressured when open frameworks start extracting actionable knowledge from PDFs without requiring a full proprietary suite.
tl;dr
RAG Anything turns multimodal documents into a retrieval system that understands text, tables, images, and equations as linked knowledge, not isolated scraps. The clever bit is the graph-centered architecture plus vision-aware querying. Worth a look for anyone building AI search, research, or enterprise copilots on top of messy documents.
Stars: 16,653 | Language: Python
