

The Push: April 19th, 2026
Paperwork tamed, architecture made auditable, and AI coding agents finally behaving in one sane interface


Paperless Ngx: Your Filing Cabinet Was the Bug
github.com/paperless-ngx/paperless-ngx | License: GPL-3.0

Tax season has a way of exposing how broken personal information systems really are. A lease lives in email, a warranty sits in a drawer, a scanned passport is buried in cloud storage under “final_final2.pdf.” Then someone asks for one document, right now, and the search turns into archaeology. Paperless Ngx lands on that exact pain point. Not “paper is annoying” in some abstract minimalist sense, but the very real fact that life admin becomes unsearchable the moment information crosses from digital to physical and back again.
The Drop: Administrative Chaos, Indexed
Plenty of products claim to organize documents, but the actual failure mode is more specific. Receipts, invoices, tax notices, medical forms, contracts, all arrive through different channels and in different formats, then slowly become a trust problem. Can that PDF be found later? Did OCR actually capture the text? Is the renamed file the latest one, or just a duplicate with a cleaner title?
Paperless Ngx exists because “store everything somewhere” is not a system. The gap is ingestion. Scanners dump image files. Email attachments pile up. Shared folders become dead zones. Search only works if documents become structured enough to retrieve by date, sender, type, tags, or full text. That sounds obvious, but honestly this is where consumer cloud storage still feels weirdly primitive.
The frustration gets sharper when the documents matter. Losing a meme is nothing. Losing an insurance claim trail is a weekend gone. Paperless Ngx treats personal and small-business paperwork like a real data problem, not just a folder problem, and that framing is why the repo has real staying power.
The Stack: Python in Front, OCR Underneath
Under the hood, Paperless Ngx runs a Django backend with an Angular frontend, packaged heavily around Docker for sane self-hosting. The important dependencies are Tesseract for OCR, optional Apache Tika and OCR tooling for broader document parsing, plus a database and Redis-backed task flow that keeps ingestion, indexing, and search from turning into one blocking mess.
The Sauce: The Inbox Is the Product
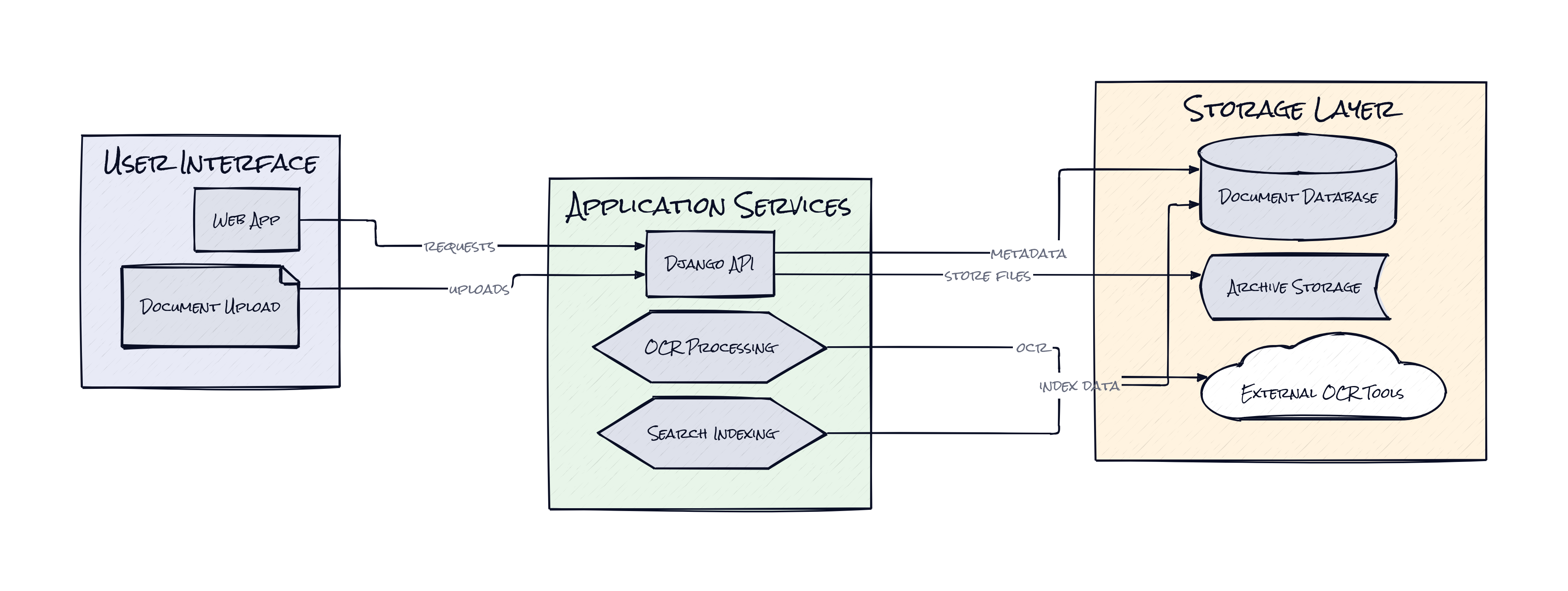
Every durable document system lives or dies on what happens the second a file appears. Paperless Ngx centers that moment through its consumer, the ingestion pipeline that watches incoming files, pulls from scanners or mail sources, extracts text, classifies metadata, checks duplicates, and then turns a raw document into a searchable record. That architecture choice is way more important than the UI.
A lot of tools treat OCR as a bolt-on. Paperless Ngx treats OCR, parsing, and metadata assignment as one continuous pipeline. The result is that search quality compounds over time because each document is not just stored, it is normalized. Correspondents, document types, tags, dates, and storage rules become reusable structure, which means the archive gets smarter as volume rises instead of collapsing into clutter.
Another smart decision is the mix of automation and override. Matching rules let users auto-assign metadata based on patterns, e.g. recurring vendors or known email senders, while manual correction stays first-class. That balance matters because paperwork is messy. Fully automated classification sounds elegant until one bad parse misfiles a tax form into “utilities.”
There is also a subtle trust advantage in keeping the whole system local-first and self-hostable. Sensitive records are not just searchable, they are inspectable as part of a system you control. For this category, that is not a nice-to-have. It is the product thesis. Even the newer document chat and embedding-based retrieval features fit that same idea: make the archive queryable without surrendering the archive.
The Move: Turn Admin Into Search
Founders, freelancers, landlords, and anyone running a household with actual complexity can put Paperless Ngx to work fast. Feed scans from a home office scanner, forward invoices from a dedicated email inbox, import old PDF dumps, then build a tagging and correspondent structure around the recurring stuff first. Utilities, payroll, taxes, legal, health, vendor contracts. The boring categories are where the payoff shows up.
From there, the strategic advantage is not neatness. It is response time. Due diligence gets easier when every contract is filterable. Expense cleanup stops being a quarterly panic when receipts are searchable by merchant and date. Family admin gets less fragile when one person’s memory is not the only index.
Small teams get a second upside: institutional memory without buying an enterprise records suite. Paperless Ngx can become the quiet system behind finance ops, compliance prep, property management, or client paperwork. That makes it a useful wedge. Start with archiving, then use saved searches, metadata rules, and full-text retrieval to turn dead files into operational infrastructure. That is where this repo stops being a hobbyist tool and starts looking like serious back-office software.
The Aura: Competence, Externalized
Paperwork has always been a tax on attention. People do not avoid documents because scanning is hard, they avoid them because retrieval feels uncertain and uncertainty creates procrastination. Paperless Ngx changes the emotional contract. Records no longer need to be remembered, only captured once and made queryable.
That shift sounds small, but it changes behavior. Households and small businesses can act like organizations with a memory layer. Search replaces recall. Process replaces piles. There is something quietly radical in that, not because filing is glamorous, but because offloading low-status cognitive work gives people back a surprising amount of confidence.
The Play: A Boring Category With Sharp Teeth
This is not a pure 0-to-1 category creation play. Document management is old, crowded, and full of enterprise incumbents. But Paperless Ngx points to a strong wedge inside a large TAM: privacy-sensitive personal admin and SMB back-office workflows that want AI-adjacent search and automation without enterprise pricing or cloud lock-in. The PMF signals are already there, 38,000-plus stars, active discussions, broad translation support, and lots of deployment pathways. The moat is not deep data network effects. It is execution speed, trust, workflow stickiness, and the pain of re-tagging and re-indexing years of records elsewhere, which creates real switching costs once the archive becomes operational.
Winners:
Fold Money: Better personal finance workflows can compound by ingesting statements and tax records into a user-controlled archive, expanding from spend tracking into document-native money management.
Rippling: Stronger SMB ops can deepen because HR, payroll, and compliance paperwork become easier to ingest and retrieve across fragmented admin systems, raising LTV through adjacent back-office use cases.
Adobe: Broader document dominance can extend as Acrobat-era workflows absorb stronger archival, OCR, and retrieval expectations that users now see as baseline.
Losers:
Veryfi: Narrow receipt extraction value erodes as open, self-hosted systems absorb more of the “scan and structure” workflow, and adaptation is hard when the wedge stays specialized.
M-Files: Premium document management positioning gets squeezed when buyers realize a lot of practical retrieval and classification can come from open infrastructure with lower CAC.
Dropbox: Generic file storage expectations weaken because folders and filename search feel thin once users get used to metadata-rich archives built for records, not just files.
tl;dr
Paperless Ngx turns scanned paperwork, email attachments, and PDF sprawl into a searchable archive with OCR, metadata rules, and surprisingly thoughtful ingestion architecture. The clever part is the pipeline that structures documents as they arrive, instead of leaving cleanup for later. Households, operators, and small teams with recurring admin pain should look.
Stars: 38,673 | Language: Python
