

The Push: April 15th, 2026
A hands-on LLM roadmap, an AI stock committee, and moonshot code preserved like a living technical archive


Dive Into Llms: The AI Course People Actually Finish
github.com/Lordog/dive-into-llms

A lot of AI education still feels weirdly split in two. On one side, glossy explainers that leave you nodding without being able to build anything. On the other, dense research repos that assume you already know half the field. Dive Into Llms lands in the middle, and that middle is way more valuable than it sounds. This repo is not trying to be a benchmark flex or a startup demo. It is trying to make large model systems legible through practice, across everything from fine-tuning to jailbreaks to GUI agents. Honestly, that breadth is the hook. The repo teaches the shape of the modern LLM stack, not just one trick.
The Drop: An LLM Curriculum With Sharp Edges
Plenty of people can explain prompting, fewer can explain why a model fails after fine-tuning, how knowledge editing changes stored facts without retraining from scratch, or why RLHF safety alignment creates a different class of tradeoff than simple prompt filtering. That gap is exactly what makes this project resonate. AI has become a product layer, a platform layer, and a research layer all at once, but the learning material around it is usually trapped in one of those modes.
Dive Into Llms comes from university coursework and research practice, and that origin matters. Instead of packaging LLMs as a single consumer abstraction, the repo breaks the field into hands-on chapters that mirror the real questions teams are asking right now: how to adapt models, how to evaluate reasoning, how to watermark output, how to test jailbreak vulnerability, how GUI agents interact with interfaces, how multimodal systems are wired, and how agent safety should be assessed. That’s a much better representation of the actual ecosystem than another “build a chatbot in 10 minutes” tutorial.
What makes the frustration feel familiar is that AI literacy has become table stakes across product, design, ops, and investing, but good materials still assume one of two extremes, either complete beginner or full-time ML engineer. This repo targets the missing middle. Not passive understanding, not PhD-only depth, but working fluency.
The Stack: Notebooks, Slides, and Research Muscle
Under the hood, Dive Into Llms is powered mostly by Jupyter Notebook workflows, paired with chapter-level markdown tutorials and lecture-style PDFs. The surrounding ecosystem appears to pull from standard Python-based LLM tooling, with examples spanning model training, inference, evaluation, safety experimentation, and lightweight demos, e.g. Gradio-style interfaces and Hugging Face-adjacent workflows.
The Sauce: The Curriculum Is the Product
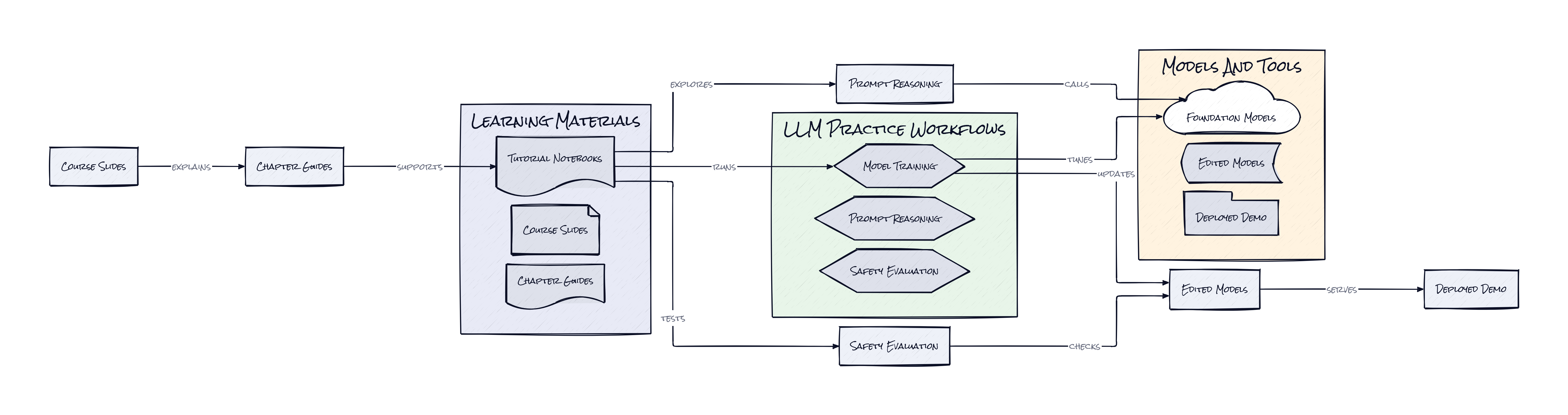
What stands out here is the decision to build a chapter architecture instead of a single monolithic course or a loose pile of notebooks. Each topic acts like a modular lens on one part of the LLM lifecycle, and together those modules form a map of the field that is surprisingly close to how actual teams experience AI adoption. That seems simple, but it is a pretty smart structural choice.
A lot of technical education repos optimize for linear progression. Learn tokenization, then transformers, then prompting, then maybe fine-tuning. Dive Into Llms organizes around capabilities and failure modes instead. One chapter covers fine-tuning and deployment, another covers reasoning, another knowledge editing, another watermarking, another jailbreaking, another multimodal systems, another agent safety. In practice, that means the learner is not just absorbing theory, but building a mental model of where interventions happen in the stack. Some changes happen at training time. Some happen at inference time. Some are governance layers. Some are attack surfaces. Some are product UX issues disguised as model issues.
That architectural framing matters because modern LLM systems are not one model sitting in isolation. They are a bundle of behaviors, safeguards, interfaces, retrieval patterns, post-processing steps, evaluation loops, and often human feedback mechanisms layered together. Dive Into Llms teaches that stack sideways. Instead of pretending one method explains everything, the repo shows multiple control surfaces. Fine-tuning changes weights. Prompting changes behavior without changing weights. Knowledge editing targets specific stored facts. Watermarking adds provenance signals. Jailbreak exercises expose policy brittleness. GUI agent lessons connect language models to visual action spaces. Safety chapters extend beyond “bad output” and into open-ended agent risk.
That is why the project feels more substantial than a tutorial dump. The educational object is not any single notebook, it is the relationship between notebooks. A reader comes away with a systems view, which is honestly what the market needs. Plenty of people can now talk about models. Fewer can reason about where to intervene when a product breaks, underperforms, or becomes unsafe.
Another smart call is format diversity. Slides, written explainers, and executable notebooks sit together, which makes the repo useful across contexts. A student can study. A builder can adapt experiments. A team lead can skim the conceptual layer first, then hand the practical layer to someone technical. That multi-format packaging quietly expands the audience without watering down the content. In startup terms, it broadens top-of-funnel while keeping depth for activation.
The Move: Turn Curiosity Into Operating Knowledge
Anyone trying to get smarter about AI strategy could use Dive Into Llms as a personal crash course, but the better move is to treat it like an internal education engine. Pick three chapters that map to real business questions. A product team exploring AI features should study prompting, fine-tuning, and evaluation. A trust and safety team should go straight to jailbreaks, watermarking, and alignment. A startup building workflow automation should focus on GUI agents, multimodal models, and agent safety.
From there, the payoff is not just learning how models work. The payoff is better judgment about vendor claims, roadmap risk, and build-versus-buy decisions. After working through this repo, a founder is less likely to confuse prompt polish with actual model improvement. A PM is more likely to ask whether a failure should be fixed with retrieval, tuning, policy constraints, or interface changes. An investor gets a better filter for what is defensible versus what is just API wrapping.
Used that way, Dive Into Llms becomes a strategic advantage. Not because everyone suddenly becomes an ML engineer, but because the team starts asking higher-quality questions. That tends to matter more than having the hottest demo.
The Aura: From AI Hype to AI Judgment
People are getting used to using AI without understanding where its behavior comes from. That works fine until the tool gives bad advice, leaks style over substance, or fails in a way that looks random but actually has a pattern. Projects like Dive Into Llms change that relationship. The user stops treating the model as a mysterious oracle and starts seeing a configurable system with known pressure points.
That shift has a broader psychological effect. Better AI education does not just create more builders, it creates more skepticism of shallow product narratives. Someone who has touched knowledge editing, attack methods, alignment, and multimodal workflows is much harder to impress with a polished wrapper and a benchmark screenshot. That is healthy. It raises the bar for the whole market.
There is also something quietly democratizing here. Advanced model behavior no longer feels reserved for frontier labs with custom infrastructure. The repo suggests that serious AI literacy can be assembled in public, through shared artifacts, with enough rigor to matter. That expectation could stick.
The Play: Education Is the Wedge, Infrastructure Is the Prize
From a VC lens, Dive Into Llms looks less like a pure content asset and more like an early signal for a broader AI learning and enablement market. This is not 0-to-1 category creation, because technical upskilling around AI already exists, but the repo points to an underbuilt segment between consumer-friendly explainers and full graduate-level ML training. That gap has real TAM across universities, enterprise enablement, workforce retraining, and founder education.
The PMF signal is not subtle. Nearly 30,000 stars on a tutorial repo, strong chapter expansion into hot topics like agent safety and GUI agents, and visible community contribution patterns suggest sustained demand rather than a one-week spike. The likely moat is not classic network effects, at least not yet. The stronger defense would come from curriculum quality, institutional trust, language accessibility, and distribution into classrooms, bootcamps, enterprise learning stacks, and cloud ecosystems. If turned into a product, CAC could stay relatively low through open source discovery, while LTV grows through certification, enterprise training, and tooling partnerships.
Winners:
Coursera: Coursera gets a clearer path to package practitioner-grade AI education that sits between hype and hardcore research. Coursera compounds because enterprise learning budgets already exist, and repos like this prove demand for applied, modular curriculum.
Notion: Notion gets more technically fluent teams documenting AI experiments, safety decisions, and model ops workflows in shared knowledge hubs. Notion compounds because better AI literacy creates more process, and more process tends to live in collaborative docs.
Hugging Face: Hugging Face gets a larger population of users ready to move from reading about models to actually testing, adapting, and evaluating them. Hugging Face compounds because education-driven adoption feeds directly into model discovery, community contribution, and tooling usage.
Losers:
Chegg: Chegg loses more of its relevance as learners seek current, hands-on AI material instead of static answer libraries. Chegg faces a hard adaptation problem because brand trust is tied to legacy study behavior, not frontier technical fluency.
Udemy: Udemy sees more pressure on generic AI courses that age badly and lack coherent architecture across topics. Udemy struggles to adapt because marketplace incentives reward volume and trend-chasing more than tightly integrated curriculum quality.
C3.ai: C3.ai loses narrative advantage when more buyers understand the difference between real AI infrastructure depth and surface-level enterprise packaging. C3.ai faces a difficult repositioning challenge because educated customers ask sharper technical questions before signing long sales cycles.
tl;dr
Dive Into Llms turns LLM education into a modular, hands-on map of the actual AI stack, from tuning and reasoning to jailbreaks, watermarking, multimodal systems, and agent safety. The clever part is the curriculum design itself. Founders, PMs, students, and investors trying to build real AI judgment should look.
Stars: 29,218 | Language: Jupyter Notebook
