

The Push: April 14th, 2026
Memory that sticks, cloned voices on your own machine, and browser-native 3D design that actually scales


Claude Mem: AI Memory Should Be Default
github.com/thedotmack/claude-mem | License: Other
A coding assistant can spend 40 minutes learning your project, finding the weird edge cases, tracing old decisions, and finally getting useful. Then the session ends, the context window resets, and the next conversation starts with the confidence of someone who just walked into the room. That loop is expensive, not just in tokens but in momentum. Claude Mem goes straight at that pain. Instead of treating each AI session like a disposable chat, it adds a persistent memory layer that captures what happened, compresses it, and feeds the relevant bits back later. Honestly, that should already be standard.
The Drop: Context Amnesia Is Expensive
Every team experimenting with coding agents runs into the same annoying pattern: the model gets smarter within a session, then instantly dumber when that session ends. Yesterday's debugging trail disappears. The rationale behind a risky refactor disappears. The little discoveries that actually matter, e.g. "this API lies in the docs" or "this migration breaks staging but not local," disappear too.
Claude Mem exists because raw transcripts are a terrible memory system. Dumping everything back into the prompt blows up token costs, adds noise, and makes retrieval worse, not better. Human users do a bad job manually curating context, and AI tools do a bad job pretending long chats equal long-term understanding. Those are different things.
What makes this frustration real is that coding assistants are already good enough to create dependency on accumulated context. Once an agent has seen your project conventions, your test failures, your dead ends, and your workarounds, starting fresh feels absurd. The gap here is not intelligence, it's continuity. Claude Code can reason in the moment. Claude Mem tries to make that reasoning survive contact with time. That sounds small, but it changes the whole interaction model from "chat with a smart stranger" to "resume work with someone who was already there."
The Stack: Hooks, Search, and Local Storage
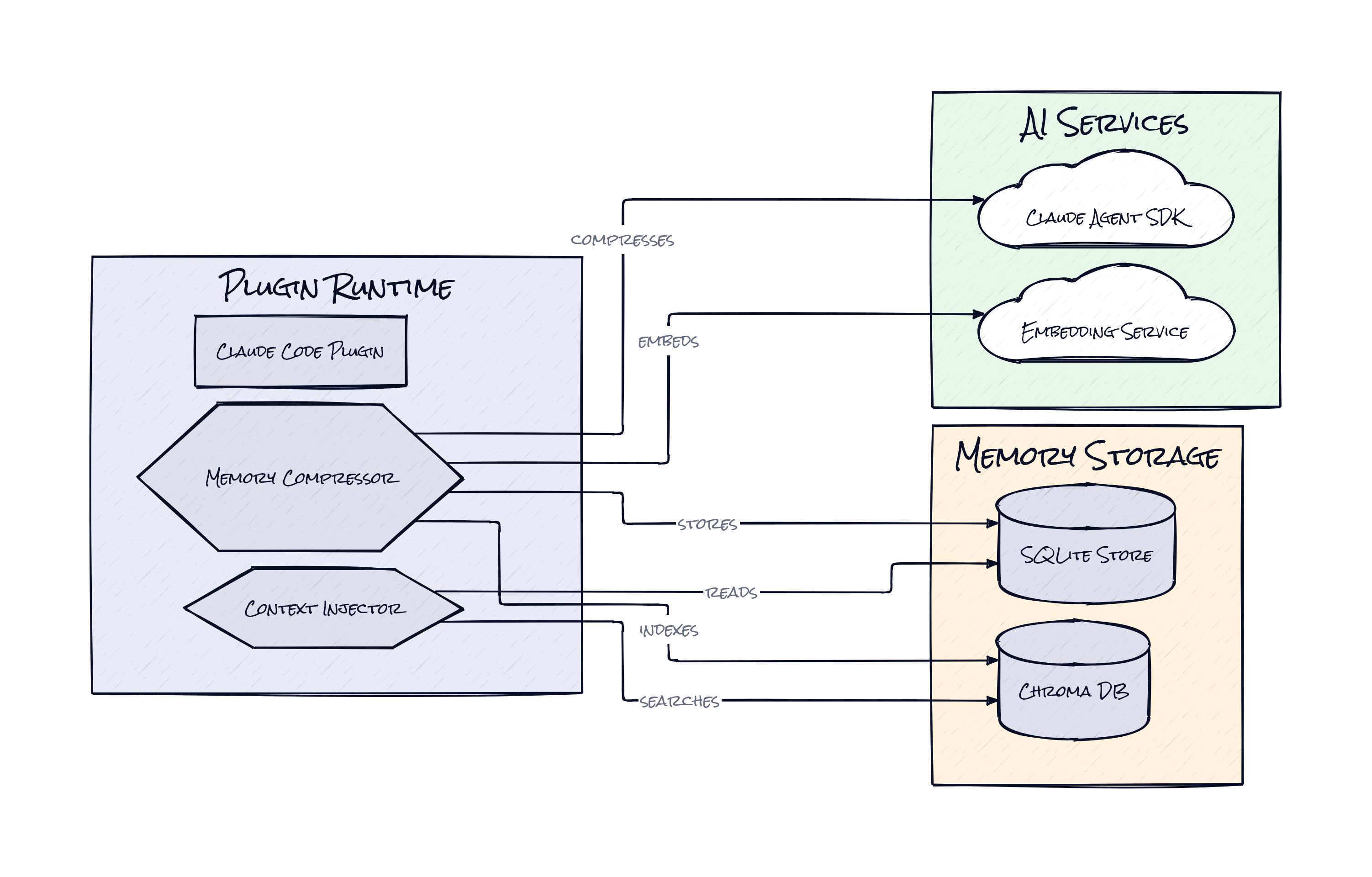
Under the hood, Claude Mem is built mostly in TypeScript, with Bun running the worker service and SQLite storing sessions, observations, and summaries locally. Search combines full-text retrieval with Chroma vector search, and the plugin layer hooks into Claude Code and related agent environments to capture events automatically.
The Sauce: Compression Before Retrieval
Session memory products usually fail in one of two ways. Either they store everything and retrieval becomes messy, or they summarize too aggressively and sand off the details that made the original work useful. Progressive Disclosure is the design choice here that makes Claude Mem worth paying attention to. Instead of treating memory as one big blob, Claude Mem stores layered representations of past work and reveals them in stages, with token cost visibility baked into the process.
Here's why that matters. A future session usually does not need the full transcript of every tool call, every mistaken assumption, every side quest. What a future session needs is a compact map of what happened, plus the ability to drill down when the summary is insufficient. Claude Mem captures observations during the workflow, compresses them into semantic summaries, stores them in local databases, and then runs hybrid search across both keyword and vector indexes. That means the system can retrieve "the auth bug from last Tuesday" even if the exact phrasing changes, while still preserving precise textual matches when wording does matter.
Architecturally, this is closer to a memory operating system than a notes app. Lifecycle hooks fire at meaningful moments in the session, a background worker service handles ingestion and retrieval outside the active chat loop, and local persistence in SQLite keeps a durable ledger of sessions, summaries, and metadata. Chroma adds semantic lookup on top, which is important because project memory is often fuzzy, not exact. You remember the shape of a problem before you remember the filename or command.
Another smart choice is that Claude Mem does not just archive context, it reinjects context. That sounds obvious, but it is the whole product. Storage alone is dead weight. Search alone depends on the user remembering to ask the right question. Reinjection turns memory into ambient infrastructure. Relevant prior work can appear at the beginning of a new session, before the model starts wandering down the same wrong path again.
I also like the privacy posture. Local-first storage plus opt-out tagging for sensitive text is a sane default for something that is effectively recording the thought process of a coding session. The interesting part is not "AI memory" as a generic feature. The interesting part is that Claude Mem treats memory as a constrained retrieval problem with compression, ranking, and staged exposure, not as a giant archive. That is why it feels more durable than a lot of flashy agent demos.
The Move: Turn Repeated AI Work Into Compounding Context
Plenty of people will install Claude Mem just to make Claude Code less forgetful. The better use is strategic: turn every AI-assisted project into a compounding asset. A founder iterating on a product can preserve architecture decisions across late-night sessions. A PM working with an engineer can keep the assistant anchored in prior tradeoffs, bug history, and naming conventions. A student building side projects can create an actual trail of reasoning instead of a pile of disconnected chats.
Teams should treat Claude Mem like institutional memory for AI workflows. Start with one repo where repeated context loss is already costing time, e.g. an app with lots of edge cases or an internal tool with weird legacy behavior. Let the plugin run for a week, then use the search and viewer tools to inspect what the system is actually retaining. That gives you a feel for where summaries are strong, where retrieval is weak, and what kinds of work produce the highest-value memory.
From there, the advantage is speed with consistency. New sessions pick up faster. Repeated bugs get resolved with prior context attached. Architecture discussions stop resetting to zero. In practice, that means fewer wasted prompts, lower token burn, and a stronger chance that the assistant behaves like a collaborator with history instead of a stateless utility.
The Aura: Software That Stops Pretending to Forget
People adapt quickly to tools that remember. Once search history, cloud docs, and chat logs became normal, forgetting started to feel like product failure rather than a fact of computing. Coding assistants have weirdly lagged on that expectation. They can write code, inspect a repo, and explain a stack trace, but after a reset they often act like none of it happened. That breaks trust more than accuracy does.
Claude Mem points at a different relationship with AI systems, one where memory becomes part of the interface instead of an optional feature. Psychologically, that changes how people delegate work. Users stop front-loading every detail and start expecting continuity. Small discoveries become durable. Repeated collaboration gets less ceremonial.
That also nudges AI from "answer engine" toward "working memory layer" for digital tasks. Not human memory, obviously. More like operational recall that follows a project over time and keeps prior reasoning available when needed. I think that behavior becomes sticky fast. Once an assistant can remember what mattered last week, the stateless version starts to feel broken.
The Play: Memory Infrastructure, Not Just a Plugin
Venture-wise, Claude Mem looks less like a cute Claude add-on and more like an early wedge into the memory layer for agentic software. The TAM is broader than coding copilots because every workflow with long-lived context, support, research, legal drafting, analytics, sales engineering, eventually wants persistent recall with controllable retrieval. This is not pure 0-to-1 category creation, memory for AI has existed as a concept, but Claude Mem does feel like a sharp product expression of a market that still lacks a dominant platform.
Fifty-five thousand stars is not casual interest. That kind of stars velocity, plus forks and documentation depth, reads like real PMF smoke in open source terms. The moat today is mostly execution speed, integration depth, and workflow fit rather than hard network effects. Over time, the stronger moat could come from behavioral switching costs: once a team's accumulated AI memory becomes part of how work gets done, ripping that layer out gets painful. CAC can stay low through open source distribution, while LTV rises if memory becomes embedded across multiple agent surfaces, not just Claude Code.
Winners:
Replit: Replit gets a stronger story around persistent coding assistance and project continuity. Replit compounds because cloud development already centralizes context, making memory features easier to turn into daily habit and paid retention.
Notion: Notion gets a clearer path to become the system that stores not just documents but AI-working history tied to projects. Notion compounds because memory plus search plus workflow context fits naturally with an existing product people already trust as a knowledge layer.
Scale AI: Scale AI gets more demand for evaluation, retrieval quality measurement, and memory tuning infrastructure around enterprise agents. Scale AI compounds because buyers adopting persistent AI workflows eventually need ways to test whether recall is accurate, safe, and cost-efficient.
Losers:
Coda: Coda loses some differentiation as "docs plus logic" when AI memory starts living directly inside workflow tools and assistants. Coda faces a hard adaptation path because memory-native behavior depends on deep ongoing interaction data, not just better document surfaces.
Chegg: Chegg loses more relevance if learning and building workflows become continuous conversations with agents that remember prior mistakes and preferences. Chegg has a tough time adapting because static answer libraries do not get stickier when personalized context becomes the expected product behavior.
Stack Overflow: Stack Overflow loses some high-intent troubleshooting traffic when assistants can retrieve prior project-specific fixes instead of sending users back to generic forum threads. Stack Overflow has a hard pivot because community Q&A is broad and public, while persistent memory is private, contextual, and embedded in the workflow itself.
tl;dr
Claude Mem turns Claude Code into a system with memory across sessions, using compression, hybrid retrieval, and context reinjection instead of brute-force transcript stuffing. The clever part is the layered recall model. Anyone betting on AI assistants for repeated project work should look closely.
Stars: 55,403 | Language: TypeScript
